
项目背景
随着业务量的日益增长,业务库用户跑男相关日志数据越来越大,为了减轻业务库压力,对数据按实时与历史的方式进行了分离。实时库保留近一个月数据,历史数据转移到了冷数据库,按年表、月表进行数据存储。业务库压力降低了,但用户跑男相关日志数据的查询时只能按分库分表结构查贸易,职能部门反馈查询很慢且不好操作,比如不能跨年查,历史数据查询经常超时等等,为了解决这些问题,我们开始尝试数据存储方式变更。
评估与预期
- 数据量:初步估算用户相关日志数据3亿+条(200GB+),跑男相关日志数据3亿+条(90GB+);
- 预估随着业务量增长,每年数据很大可能超150GB+;
- 预期数据检索速度:200毫秒左右;
以下是各数据库对比:
| Mysql | Hadoop | Mongodb | ElasticSearch | |
| 容量扩展 | 中 | 海量 | 较大 | 较大 |
| 查询灵活性 | 非常好,支持sql | 非常好,支持sql | 较好,但是单集合数据量超过10亿条,即使简单条件查询性能也不理想,不如Elasticsearch倒排索引快 | 较好,关联查询较弱,但是可以全文检索,DSL语言可以处理过滤、匹配、聚合、排序等操作 |
| 写入速度 | 中等 | 慢 | 较快 | 较快 |
什么是Elasticsearch?
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
基本概念
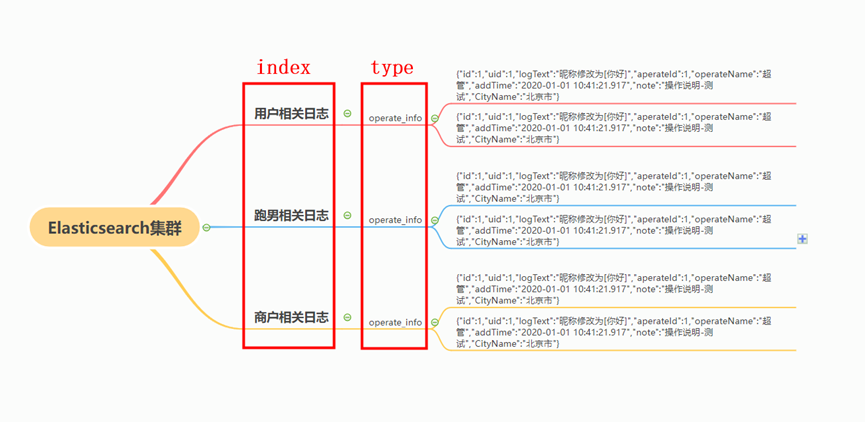
- Index(索引)
动词,相当于mysql中的insert;名词,相当于mysql的Database;
- Type(类型)7.0废弃
在index(索引)中,可以定义一个或多个类型,类似于mysql中的table,同一种类型的数据放在一起;
- Document(文档)
保存在某个索引(Index)下、某种类型(Type)的一个数据(Document),文档是json格式的数据,Document相当于mysql中某个table数据;
- 倒排索引
分词:将整句拆分为单词
为什么选择Elasticsearch
- 相较于其它几种数据库,ES技术栈的经验相对丰富;
- ES是一种容纳较大规模数据并且交互性好的数据库,可以在容量和交互性上达到一个非常不错的平衡;
- Elasticsearch 很快。由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
- Elasticsearch 包含一系列广泛的功能(支持全文检索、倒排索引,DSL语言可以处理过滤、匹配、排序、聚合等各种操作)。除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
- Elasticsearch 具有分布式的本质特征,使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,副本机制能够保证数据的可靠性,即使有节点宕机也可以保证数据不丢失。
- 集群中,若主节点挂掉了,或者是挂了其中一个,在设置了master.nod参数时,如果主节点挂掉,其他的节点会被重新选举为主节点,继续接力。
- 集群中,所有节点都挂掉了,解决问题开机后,ES会自动的寻找备份节点/文件恢复数据,在找到备份之后,ES会在不影响系统的情况下恢复数据,同时继续接力
导入数据过程
在单元测试过程中发现,使用Elasticsearch.Net的 Bulk api进行数据写入,大概每秒插入3000条左右,7+亿条数据使用这种方式导入到Es中,耗费时间太长。而用REST API的_bulk来批量插入,速度会非常快,可以达到5 w+条每秒。但是需要先定义一定格式的Json文件,然后再用curl命令去执行Elasticsearch的_bulk来批量插入。这就要求把数据写进Json文件,然后再通过批处理,执行文件插入数据。另外在生成Json格式文件不能过大,文件过大会导致一些意想不到的情况,所以建议生成的文件一个10M左右,然后分别去执行这些小文件就可以了。
数据转移流程
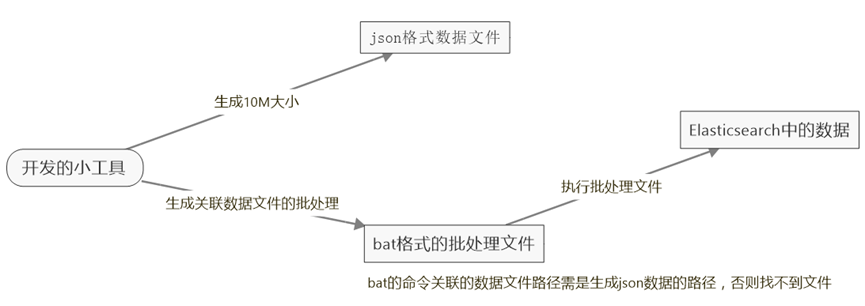
Json格式数据文件格式展示

bat格式批处理文件

核心代码
转移过程核心代理很简单,如下:
if (!Directory.Exists(@"D:\EsData\UserOperateLog"))
Directory.CreateDirectory(@"D:\EsData\UserOperateLog");
using (FileStream fs = new FileStream($"D:\\EsData\\UserOperateLog\\{tbName}_{pageIndex}.json", FileMode.Create))
{
using (StreamWriter sw = new StreamWriter(fs, new UTF8Encoding(false)))
{
StringBuilder sb = new StringBuilder();
foreach (var baseItem in baseDataList)
{
string esAction = isCreate ? "index" : "update";
baseItem.CityName = GetCityName(baseItem.UserCityID ?? 0);
baseItem.UserTypeText = Enum.GetName(typeof(UserTypeEnum), baseItem.UserType ?? 0);
sb.Append($"{{\"{esAction}\": {{ \"_index\":\"user_operatelog_v1\", \"_type\":\"operatelog\", \"_id\": \"{baseItem.Id}\"}}");
sb.Append("}");
sb.Append(Environment.NewLine);
sb.Append(SerializeData(baseItem));
sb.Append(Environment.NewLine);
sw.Write(sb.ToString());
sb.Length = 0;
}
}
}
batStrBild.Append($"curl -u {esUserName}:{esPassword} -s -H \"Content-Type: application/json\" -XPOST {esUrl.Trim('/')}/user_operatelog_v1/operatelog/_bulk?pretty --data-binary ");
batStrBild.Append(@"@D:\EsData\UserOperateLog\" + tbName + "_" + pageIndex + ".json" + Environment.NewLine);
查询结果
从正式数据导入结果来看,Elasticsearch的搜索速度能够满足查询要求。
核对数据的过程中,在3亿+数据时,根据城市CityID和添加时间addTime在一年范围的数据,每次千条数据不到200毫秒就完成查询。
首次查询会慢(将磁盘文件里的数据自动缓存到 filesystem cache 里面),但是之后就会很快,而且同一查询条件查询越多,查询就越快(已经缓存到filesystem cache里面)。7亿条数据,大概占用500G空间左右,相比业务库存储的数据,要大1.8倍左右,但搜索速度比较满意。
