
一、什么是Selenium
Selenium 是一个用于 Web 应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括Mozilla Firefox,Safari,Chrome,Opera,Edge 等
二、Selenium 优势
1、免费开源
2、小巧,对于不同的语言而言,只是一个包的大小
3、支持多语言,python,java 等
4、支持多平台,多浏览器
三、Selenium 原理
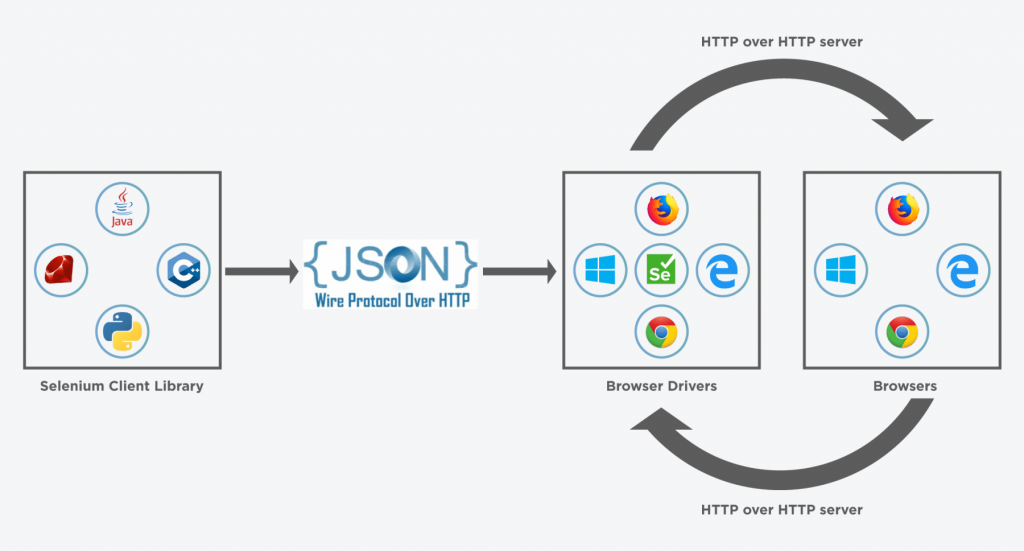
上图所示Selenium Client Library就是我们平时使用的编码语言,包括 java、python、C#等。可以看到这些语言并没有直接与 Browser Drivers 进行通信,而是通过了 JSON WireProtocol,这就是 webdriver 协议。
简单的说他定义了一套接口规范,以我们最熟悉的点击操作为例,他对应的接口协议是:
POST /session/{session id}/element/{element id}/click
这样以来,无论我们编码使用 python 代码来执行点击操作:
driver.find_element_by_id(“”).click()
还是以 java 代码执行点击操作:
driver.findElement(By.id(“”)).click();
都会通过 selenium 客户端的程序将 click 操作转化成对应的 webdriver 协议。这样对于 Browser Drivers 来说只需要解析具体协议,而无需关注客户端使用的是哪种代码了,这就是 selenium 支持多种语言的原理。
在 Browser Drivers 中可以看到各个浏览器的 driver,这里我们以 chromedriver 为例进行讲解。在代码中直接 new ChromeDriver() 将会启动一个 ChromeDriver 进程,ChromeDriver 是一个独立的服务,它是 google 为网站开发人员提供的自动化测试接口,它是 selenium 和 chrome 浏览器进行通信的桥梁。chromeDriver 解析 webdriver 协议,然后根据解析结果,调用与之对应的 Remote Debugging 协议来操控 chrome 浏览器,它可以和浏览器内核进行交互进而操控浏览器
四、浏览器驱动
当 selenium 升级到 3.0 之后,对不同的浏览器驱动进行了规范。如果想使用 selenium 驱动不同的浏览器,必须单独下载并设置不同的浏览器驱动。
各浏览器驱动下载地址:
Firefox 浏览器驱动:geckodriver
Chrome 浏览器驱动:chromedriver , taobao镜像
Edge 浏览器驱动:MicrosoftWebDriver
Opera 浏览器驱动:operadriver
五、python 安装Selenium
通过命令安装:pip install selenium
注:如果电脑上既有 python2,又有 python3,在执行 pip 命令安装时,要注意区分
六、设置浏览器驱动
1、设置浏览器的地址非常简单。 我们可以手动创建一个存放浏览器驱动的目录,如: C:\driver ,将下载的浏览器驱动文件放到该目录下,然后将此目录路径放在环境变量 Path 下
2、python 验证不同的浏览器驱动是否正常使用
from selenium import webdriver
driver = webdriver.Firefox() # Firefox浏览器
driver = webdriver.Chrome() # Chrome浏览器
driver = webdriver.Edge() # Edge浏览器
driver = webdriver.Opera() # Opera浏览器
3、测试是否正常打开浏览器
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com') # 打开百度
print(driver.title) # 获取网页title
driver.quit() # 关闭浏览器七、常用功能
1、元素定位
常用元素定位为 8 种,分别为:
通过 id 定位:find_element_by_id()
通过 id 定位一组元素:find_elements_by_id()
通过 name 定位:find_element_by_name()
通过 name 定位一组元素:find_elements_by_name()
通过 class name 定位:find_element_by_class_name()
通过 class name 定位一组元素:find_elements_by_class_name()
通过 tag name 定位:find_element_by_tag_name()
通过 tag name 定位一组元素:find_elements_by_tag_name()
通过 link text 定位:find_element_by_link_text()
通过 link text 定位一组元素:find_elements_by_link_text()
通过部分 link text 定位:find_element_by_partial_link_text()
通过部分 link text 定位一组元素:find_elements_by_partial_link_text()
通过 xpath 定位:find_element_by_xpath()
通过 xpath 定位一组元素:find_elements_by_xpath()
通过 css 定位:find_element_by_css_selector()
通过 css 定位一组元素:find_elements_by_css_selector()
注意:如果定位一组元素,则在 element 后面加一个 s
2、控制浏览器
- 控制浏览器大小
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# 参数数字为像素点
print("设置浏览器宽500、高500显示")
driver.set_window_size(500, 500)
driver.quit()
- 控制浏览器前进后退
from selenium import webdriver
driver = webdriver.Firefox()
#访问百度首页
first_url= 'http://www.baidu.com'
print("access %s" %(first_url))
driver.get(first_url)
#访问新闻页面
second_url='http://news.baidu.com'
print("access %s" %(second_url))
driver.get(second_url)
#返回(后退)到百度首页
print("back to %s "%(first_url))
driver.back()
#前进到新闻页
print("forward to %s"%(second_url))
driver.forward()
driver.quit()3、WebDriver 常用方法
- clear(): 清除文本
- send_keys (value): 模拟按键输入
- click(): 单击元素
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
driver.quit()
- submit():用于提交表单
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
search_text = driver.find_element_by_id('kw')
search_text.send_keys('selenium')
search_text.submit()
driver.quit()4、设置元素等待
WebDriver 提供了两种类型的等待:显式等待和隐式等待
显式等待使 WebdDriver 等待某个条件成立时继续执行,否则在达到最大时长时抛出超时异常(TimeoutException)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
element = WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located((By.ID, "kw")))
element.send_keys('selenium')
driver.quit()
隐式等待并不影响脚本的执行速度。其次,它并不针对页面上的某一元素进行等待。当脚本执行到某个元素定位时,如果元素可以定位,则继续执行;如果元素定位不到,则它将以轮询的方式不断地判断元素是否被定位到。假设在第 5 秒定位到了元素则继续执行,若直到超出设置时长(10 秒)还没有定位到元素,则抛出异常。
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
from time import ctime
driver = webdriver.Chrome()
# 设置隐式等待为10秒
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
try:
print(ctime())
driver.find_element_by_id("kww").send_keys('selenium')
except NoSuchElementException as e:
print(e)
finally:
print(ctime())
driver.quit()八、Python+Selenium 实现识别图片验证码登录
1、打开网站设置要访问的网站地址,并把窗口最大化,这是能保证在电脑上每次截取的图片都是相同的大小
url = "https://www.xxxxx.com"
# 1、打开浏览器,最大化浏览器
driver = webdriver.Chrome()
driver.get(url)
#driver.implicitly_wait(10)#隐式等待10s
driver.maximize_window()#最大化窗口
2、截取带图片验证码的网站内容,并保存在本地
driver.save_screenshot("H://test/01.png")#截取屏幕内容,保存到本地
也可以通过 id 或者 Xpath 的方式定位到图片验证码的方式直接获取图片验证码,保存在本地
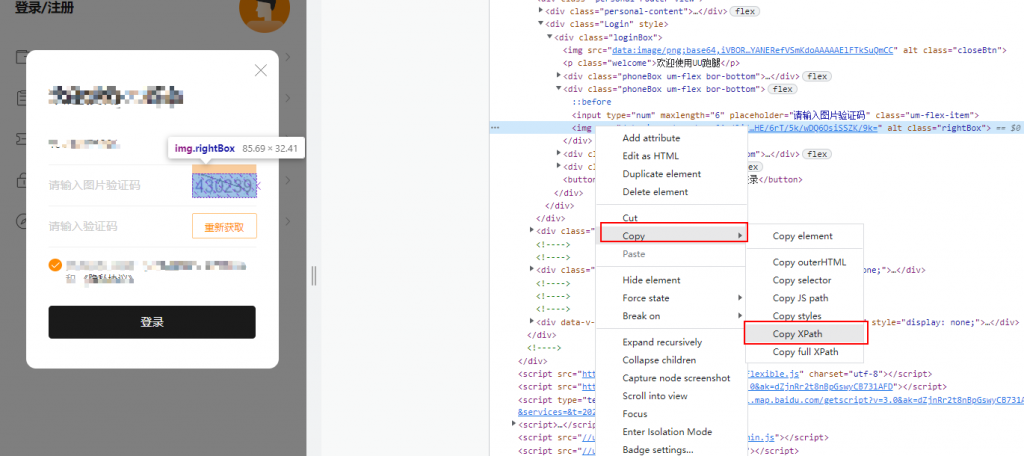
3、使用第三方库对图片进行识别(pytesseract 和ddddocr 都可以识别图片验证码)
a、使用pytesseract 识别图片验证码
定位在图片中验证码所在的位置,四个参数分别代表图片验证码的左,上,右,下坐标,可以通过 windows 自带的画图工具获取
当使用通过定位获取到验证码的方式时,可以跳过手动获取图片验证码的流程,直接跳转到图像处理步骤
ran = Image.open("H://test/01.png")#打开截图,获取验证码位置,截取保存验证码
box = (564, 395, 643, 423) # 获取验证码位置,代表(左,上,右,下)
ran.crop(box).save("H://test/02.png")#把获取的验证码保存
#获取验证码图片,读取验证码
imageCode = Image.open("H://test/02.png") #打开保存的验证码图片
#imageCode.load()
# 图像增强,二值化
sharp_img = ImageEnhance.Contrast(imageCode).enhance(2.0)
sharp_img.save("H://test/03.png")#保存图像增强,二值化之后的验证码图片
sharp_img.load() # 对比度增强
time.sleep(2)
print(sharp_img)#打印图片的信息
code = pytesseract.image_to_string(sharp_img).strip()#读取验证码
b、使用 ddddocr 识别图片验证码
先将图片保存在本地,然后可以直接通过二进制读取图片,进行识别
# 创建对象
ocr = ddddocr.DdddOcr()
# 使用二进制的方式读取图片
with open('./images/code1.png', 'rb') as f:
img_tytes = f.read()
# 调用识别方法
res = ocr.classification(img_tytes)
print(f'验证码为:{res}')
4、定位账号密码等输入框,并输入相关内容
name=driver.find_element_by_id("username")#定位账号输入框
password=driver.find_element_by_id("password_1")#定位密码输入框
code1=driver.find_element_by_id("user_ck")#定位验证码输入框
name.send_keys('username')#给定位账号的输入框中输入值
password.send_keys('password')#给定位密码的输入框中输入值
code1.send_keys(code)#给定位验证码的输入框中输入读取到的验证码
5、定位并点击按钮
driver.find_element_by_name("yt0").click()#点击登录
6、最后关闭页面
#关闭浏览器
driver.quit()九、问题和解决方案
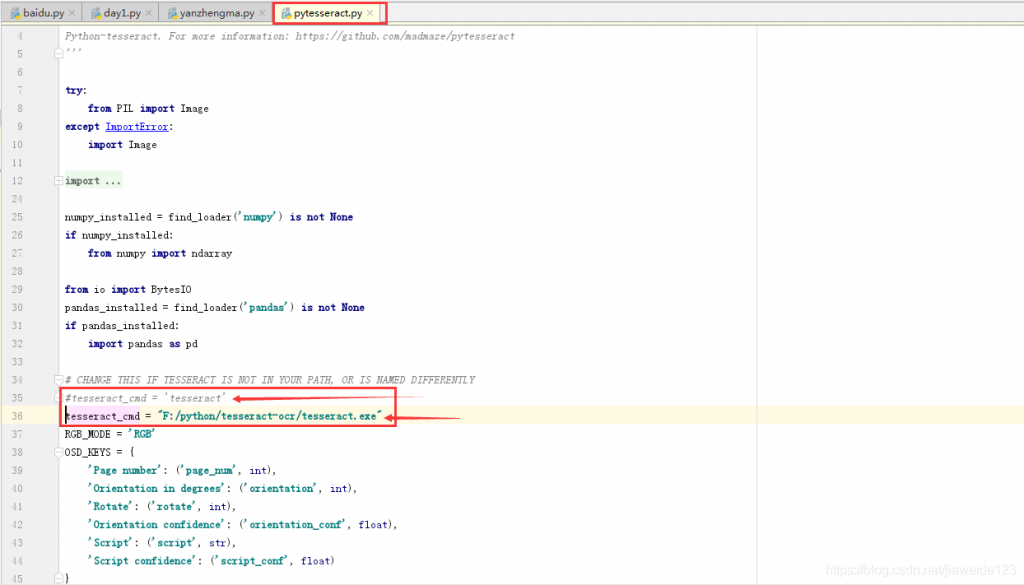
在使用pytesseract图片识别过程中,会报错 tesseract-ocr 相关信息
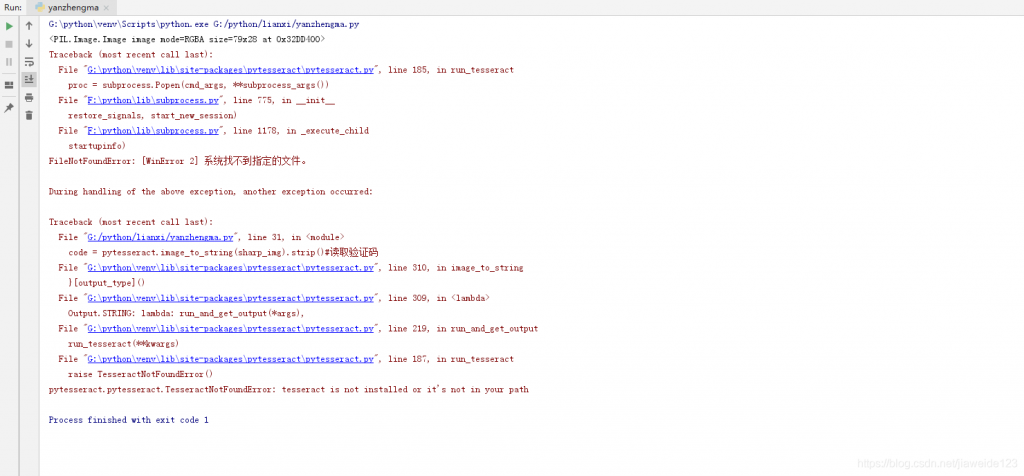
这个时候,可以通过https://github.com/UB-Mannheim/tesseract/wiki中下载 tesseract-ocr
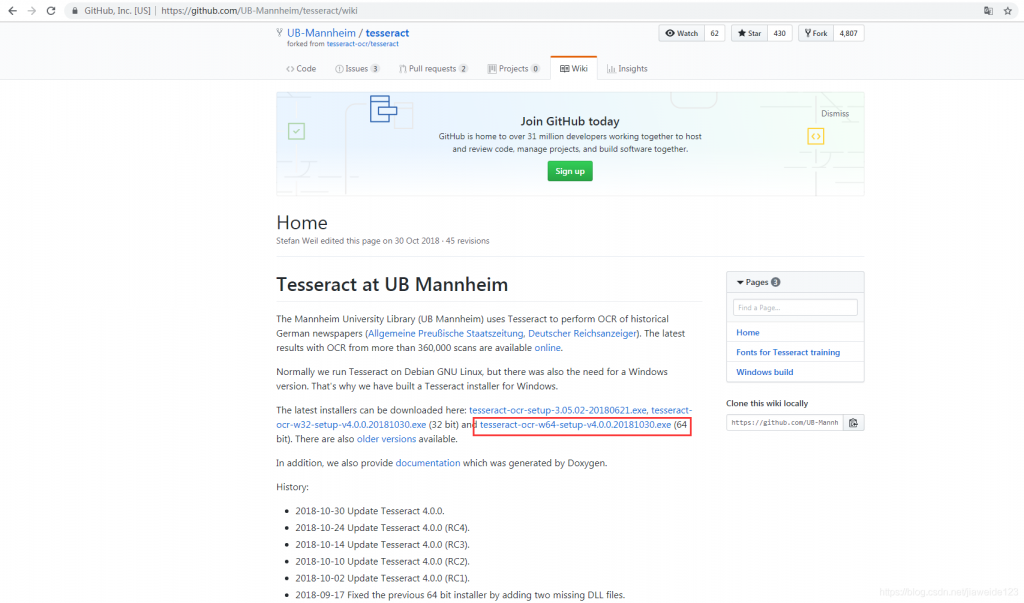
打开 pytesseract.py 文件,找到 tesseract_cmd,将原来的注释掉,然后添加新的:tesseract_cmd=”新下载的tesseract-ocr 保存路径/tesseract.exe”,即可解决此问题
参考文献
Ravinder Singh. Selenium WebDriver Achitecture[EB/OL]. 2021 年 11 月 22 日[2022 年 7 月 20 日]. https://www.toolsqa.com/selenium-webdriver/selenium-webdriver-architecture/.