
遇到的问题
在互联网移动端的产品设计上,一定少不了一些初始化配置、缓存的配置项等信息在初始化或者某些实际获得后保存下来,在网络请求或者页面加载时使用;比如我们登录的用户信息,用户当前位置信息、城市项或平台配置等。而这些配置项或者一些常用信息,通常是以 key-value 的形式进行存储和读取的,在移动端通常使用一些轻量化的存储方式,如 Android 的 SharedPreferences、Ios 的 NSUserDefaults、Web 端的 LocalStorage。
然而,随着移动互联网时代的崛起,伴随着大量的需求不断涌出和产品版本迭代,移动端APP已经从当初的几十K到几M大小,生长到了如今的几十M到一二百M,甚至于某些游戏 APP 安装后加上数据包大小,已经超过1个G。越来越多的配置和信息,需要再app运行过程中,不断地读/写;在 Android 诞生之初就肩负重任的轻量级数据存储框架 SharedPreferences,显然已经不堪重负,被广大 Android 程序猿产生又爱又恨的感情。爱她使用方便,不用新起线程,随用随丢;恨它性能不稳定,时长引发 APP 发生 ANR。
产生的原因
SharedPreferences存在的问题
1. 读写的效率比较低
- 读写方式:直接I/O
- 数据格式:xml
- 写入方式:全量更新
由于 SharedPreferences 使用的 xml 格式保存数据,所以每次更新数据只能全量替换更新数据;这意味着如果我们已经写入了100个数据,现在只需要更新其中一项数据,也需要将所有数据转化成 xml 格式,然后再通过 io 写入文件中,这也导致 SharedPreferences 的写入效率比较低的一个原因。
2. commit 导致的ANR
public boolean commit() {
// 在当前线程将数据保存到mMap中
MemoryCommitResult mcr = commitToMemory();
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, null);
try {
// 如果是在singleThreadPool中执行写入操作,通过await()暂停主线程,直到写入操作完成。
// commit的同步性就是通过这里完成的。
mcr.writtenToDiskLatch.await();
} catch (InterruptedException e) {
return false;
}
/*
* 回调的时机:
* 1\. commit是在内存和硬盘操作均结束时回调
* 2\. apply是内存操作结束时就进行回调
*/
notifyListeners(mcr);
return mcr.writeToDiskResult;
}如上代码,commit 有返回值,表示修改是否提交成功;commit 提交是同步的,直到磁盘操作成功后才会完成,所以当数据量比较大或者并发操作读写比较多时,使用 commit 很可能引起 ANR。
3. Apply 导致的ANR
虽然 commit 是同步的,但是 SharedPreferences 同时也提供了异步的 apply。apply 是将修改数据原子提交到内存, 而后异步地提交到硬件磁盘,。在多个并发的同步提交 commit 的时候,他们会等待正在处理的commit 保存到磁盘后在操作,降低了效率;而 apply 只是原子的提交到内存,后面如果还有有调用 apply 的函数的将会直接覆盖前面的内存数据,这样从一定程度上提高了很多效率。
但是apply同样会引起ANR的问题:
public void apply() {
final long startTime = System.currentTimeMillis();
final MemoryCommitResult mcr = commitToMemory();
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
mcr.writtenToDiskLatch.await(); // 等待
......
}
};
// 将 awaitCommit 添加到队列 QueuedWork 中
QueuedWork.addFinisher(awaitCommit);
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);
}
};
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);
}将一个 awaitCommit 的 Runnable 任务,添加到队列 QueuedWork 中,在 awaitCommit 中会调用 await() 方法等待,在 handleStopService 、 handleStopActivity 等等生命周期会以这个作为判断条件,等待任务执行完毕;将一个 postWriteRunnable 的 Runnable 写任务,通过 enqueueDiskWrite 方法,将写入任务加入到队列中,而写入任务将在一个线程中执行完成;
为了保证异步任务及时完成,当生命周期处于 handleStopService() 、 handlePauseActivity() 、 handleStopActivity() 的时候会调用 QueuedWork.waitToFinish() 会等待写入任务执行完毕。
private static final ConcurrentLinkedQueue<Runnable> sPendingWorkFinishers =
new ConcurrentLinkedQueue<Runnable>();
public static void waitToFinish() {
Runnable toFinish;
while ((toFinish = sPendingWorkFinishers.poll()) != null) {
toFinish.run(); // 相当于调用 `mcr.writtenToDiskLatch.await()` 方法
}
}sPendingWorkFinishers 是 ConcurrentLinkedQueue 实例,apply 方法会将写入任务添加到 sPendingWorkFinishers 队列中,在单个线程的线程池中执行写入任务,线程的调度并不由程序来控制,也就是说当生命周期切换的时候,任务不一定处于执行状态;toFinish.run() 方法,相当于调用 mcr.writtenToDiskLatch.await() 方法,会一直等待;waitToFinish() 方法就做了一件事,会一直等待写入任务执行完毕,其它什么都不做,当有很多写入任务,会依次执行,当文件很大时,效率很低,造成 ANR 也就不奇怪了。
4. 读数据get() 导致ANR
不仅是写入操作,所有 get() 方法都是同步的,在主线程调用 get 方法,必须等待 SharedPreferences 加载完毕,也有可能导致 ANR ;调用 getSharedPreferences() 方法,最终会调用 SharedPreferencesImpl.startLoadFromDisk() 方法开启一个线程异步读取数据。
private final Object mLock = new Object();
private boolean mLoaded = false;
private void startLoadFromDisk() {
synchronized (mLock) {
mLoaded = false;
}
new Thread("SharedPreferencesImpl-load") {
public void run() {
loadFromDisk();
}
}.start();
}当开启一个线程异步读取数据,当我们正在读取一个比较大的数据,还没读取完,接着调用 get() 方法。
在同步方法内调用了 wait() 方法,会一直等待 getSharedPreferences() 方法开启的线程读取完数据才能继续往下执行,如果读取几 KB 的数据还好,假设读取一个大的文件,势必会造成主线程阻塞。
public String getString(String key, @Nullable String defValue) {
synchronized (mLock) {
awaitLoadedLocked();
String v = (String)mMap.get(key);
return v != null ? v : defValue;
}
}
private void awaitLoadedLocked() {
......
while (!mLoaded) {
try {
mLock.wait();
} catch (InterruptedException unused) {
}
}
......
}解决的方向
对于在移动端上 SharedPreferences 的表现不如意,但是大家还是一直在用,一是因为他太好用了,太方便了:无需引用任何第三方的东西,0学习成本,官方API 简单封装即可拿来用。二是对于 SharedPreferences 产生的 ANR 并非必现:一般在 CPU 紧张、高频读写、存储数据的文件越来越大时才会发生,所以大部分情况在测试阶段根本不会发生,在线上生产环境用户积累一定多的数据,操作频率、手机配置低、CPU 内存等硬件资源紧张时才会发生,所以也很难排查到。
对此问题,目前流行的有两个解决方向:一、增加读取效率;二、异步。
MMKV-基于mmap的高性能通用key-value组件
MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今在微信上使用,其性能和稳定性经过了时间的验证。现在也已移植到 Android / macOS / Win32 / POSIX 平台,一并开源。
相较于 SharedPreferences,MMKV 有以下优点:
- MMKV 实现了 SharedPreferences 接口,可以无缝切换
- 通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 app 有 crash 导致数据丢失。
- MMKV数据序列化方面选用 protobuf 协议,protobuf 在性能和空间占用上都有不错的表现
- SharedPreferences 是全量更新,MMKV 是增量更新,天然具有性能优势
- MMKV 支持安卓进行多进程访问,相较于SharedPreferences 还要使用 ContentProvider 进行数据共享, MMKV 就从迁移到 Android 平台时就设计了对多进程访问和数据校验的支持
- MMKV 采用了AES CFB-128 算法进行加密解密,天然支持数据加密,而 SharedPreferences 需要自己手动实现加密,否则就是明文存储
- 腾讯、百度、头条都有使用,已开源,很成熟
MMKV 的起源
在微信客户端的日常运营中,时不时就会爆发特殊文字引起系统的 crash,微信团队需要在特殊文字引发crash 时准确的对此文字进行计数;技术方案是在关键代码前后进行计数器的加减,通过检查计数器的异常,来发现引起闪退的异常文字。在会话列表、会话界面等有大量 cell 的地方,希望新加的计时器不会影响滑动性能;另外这些计数器还要永久存储下来——因为闪退随时可能发生。这就需要一个性能非常高的通用 key-value 存储组件,在考察了 SharedPreferences、NSUserDefaults、SQLite 等常见组件,发现都没能满足如此苛刻的性能要求。考虑到这个防 crash 方案最主要的诉求还是实时写入,而 mmap 内存映射文件刚好满足这种需求,最后尝试通过它来实现了一套 key-value 组件。
MMKV 的原理
- 内存准备
通过 mmap 内存映射文件,提供一段可供随时写入的内存块,APP 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。 - 数据组织
数据序列化方面 mmkv 选用 protobuf 协议,protobuf 在性能和空间占用上都有不错的表现。考虑到要提供的是通用 KV 组件,key 可以限定是 string 字符串类型,value 则多种多样(int/bool/double 等)。要做到通用的话,考虑将 value 通过 protobuf 协议序列化成统一的内存块(buffer),然后就可以将这些 KV 对象序列化到内存中。 - 写入优化
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,需要有增量更新的能力:将增量 KV 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 mmkv 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。 - 空间增长
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。例如同一个 key 不断更新的话,是可能耗尽几百 M 甚至上 G 空间,而事实上整个 KV 文件就这一个 key,不到 1k 空间就存得下。这明显是不可取的。MMKV 需要在性能和空间上做个折中:以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 排重,尝试序列化保存排重结果;排重后空间还是不够用的话,将文件扩大一倍,直到空间足够。 - 数据有效性
考虑到文件系统、操作系统都有一定的不稳定性,MMKV 另外增加了 crc 校验,对无效数据进行甄别。
MMKV 的关键技术
mmap 内存映射(memory mapping)
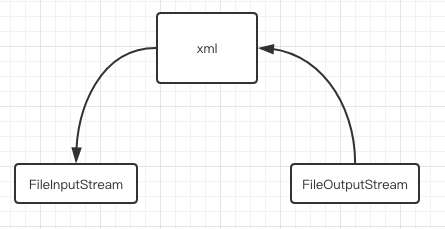
Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页(dirty page)到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read, write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映到用户空间,从而可以实现不同进程间的文件共享。
Protobuf协议
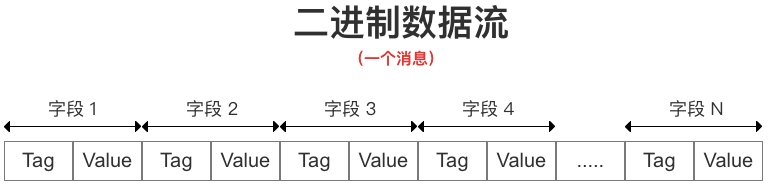
Protobuf (Google Protocol Buffers) 是 Google 提供一个具有高效的协议数据交换格式工具库(类似Json),但相比于Json,Protobuf 有更高的转化效率,时间效率和空间效率都是JSON的3-5倍。MMKV 的序列化/反序列化使用 Protobuf 实现,其采用了以 T – V 方式对数据进行二进制数据流存储,空间占存少、数据量精简,能以最少的数据量能表示最多的信息。
DataStore 基于Flow实现异步存储,避免因为阻塞主线程带来的ANR问题
果然对于 SharedPreferences 存在的问题,现在谷歌自己都看不下去了,谷歌自2020年开始推出 Datastore 旨在替代原有 SharedPreferences,解决 SharedPreferences 的不足。Jetpack DataStore 是一种数据存储解决方案,允许使用协议缓冲区存储键值对或类型化对象。DataStore 使用 Kotlin 协程和 Flow 以异步、一致的事务方式存储数据。
DataStore 相比 SharedPreferences 有以下特点:
- DataStore基于事务方式处理数据更新。
- DataStore基于Kotlin Flow 存取数据,默认在 Dispatchers.IO 里异步操作,避免阻塞UI线程,且在读取数据时能对发生的 Exception 进行处理。
- 不提供 apply()、commit() 存留数据的方法。
- 可以监听到操作成功或者失败结果。
- 可以使用Proto DataStore 将数据作为自定义数据类型的实例进行存储。此实现要求使用协议缓冲区来定义架构,但可以确保类型安全。
- 支持自动完成 SharedPreferences 迁移到 DataStore,保证数据一致性,不会造成数据损坏。
实测效率
不能只相信官网数据,“实践是检验真理的唯一标准”,当然要进行自己验证了。
- 以下是测试机nova 7 5G HarmonyOS 2.0.0上进行测试的数据,连续随机读写String
- 次数单位/次 时间单位/毫秒,key和value每次随机生成,且字符长度相同
- DataStore(同步)时间长并是说写入很慢,时间长是因为依赖协程的调度,从开始到完成的结果回调时间;DataStore并没有提供同步的api
| 写操作 | SharedPreferences | MMKV | DataStore(同步) | DataStore(异步) |
| 100次 | 1-6 | 0-2 | 400-2000 | 0-1 |
| 1000次 | 40-500(ANR) | 1-8 | 2000-30000 | 0-1 |
| 10000次 | 90-5000(ANR) | 20-30 | 3000-90000 | 0-2 |
| 100000次 | /(ANR) | 140-300 | / | 0-2 |
方案分析
之前已经对3者进行了性能比较,得出的结果是:
DataStore 是Google推出取代 SharedPreferences一种数据存储解决方案;
优势是支持协程异步调用避免阻塞UI线程,调用时主线程几乎不占任何时间;
劣势是无同步api,业务中key-value的存/取操作改为协程调用,在IO线程执行,改动成本太大;如果需要完成写入后再处理事件,写入时间不可控(可能很慢);事实上如果将其转为同步,那么性能并不会比SharedPreferences更优秀,实际打印回调时间来看,反而需要等待更久;
MMKV 可以说是效率相当高,读效率接近了 SharedPreferences 完成初始化后的读取速度( SharedPreferences 首次读取需要加载,后面读很快),写的效率也非常接近读的效率,也就是说几乎 MMKV 的读写速率都相当于从内存中读写了。更大的优势是 MMKV 的 api 是同步的,使用非常简单,因为项目中的配置项读取现行代码逻辑都是同步存取的,业务代码不需要发生大的改动,成本极低,所以 MMKV 非常合适;
所以最后选择了使用MMKV对项目中SharedPreferences存储进行改进优化。
落地与实践
由于 MMKV 设计的初衷是为了代替性能不高的 SharedPreferences,所以考虑了 SharedPreferences 向MMKV迁移的成本,在设计上兼容了很多 SharedPreferences 的用法,经过简单的包装,便可以使得业务代码几乎零改动,丝毫不用担心因为大量配置数据的迁移导致工作量很大。
MMKV的使用
com.uupt:mmkv 是基于业务的使用习惯,对 MMKV 进行了封装,实现根据文件名自动检测 MMKV 是否已经初始化完毕;以及根据初始化数据文件时,自动完成从 SharedPreferences 到 MMKV 的数据拷贝迁移,主要包含工具类 UuKvUtils 和包装类 UuKv。
第一步:引用依赖库
implementation 'com.uupt:mmkv:1.0.0.0' 第二步:完成初始化
推荐在application的onCreate完成初始化
- 方式一:初始化,默认目录:files/mmkv
UuKvUtils.init(this) - 方式二:在某个目录完成初始化
val dir = filesDir.absolutePath + "/mmkv_2";
UuKvUtils.init(this,dir) 第三步:实例化UuKv
- 方式一:初始化,默认文件:mmkv.default
val mKv = UuKv()- 方式二:单独实例化一个文件
val mKv = UuKv("fileName") - 方式三:支持数据加密
val mKv = UuKv("fileName",UuKv.MODE_SINGLE_PROCESS,"cryptKey1") - 方式四:支持多进程访问,多进程访问的数据一定要加密
val mKv = UuKv("fileName",UuKv.MODE_MULTI_PROCESS,"cryptKey1")第四步:读/写操作
写(存)数据
mKv.putString("key",value)
mKv.putFloat("key",value)
mKv.putInt("key",value)
mKv.putBoolean("key",value)
mKv.putDouble("key",value)
mKv.putStringSet("key",value)
mKv.putBytes("key",value)
mKv.putParcelable("key",value)读(取)数据
mKv.getString("key",defaultValue)
mKv.getFloat("key",defaultValue)
mKv.getInt("key",defaultValue)
mKv.getLong("key",defaultValue)
mKv.getBoolean("key",defaultValue)
mKv.getStringSet("key",defaultValue)
mKv.getBytes("key",defaultValue)
mKv.getParcelable("key",defaultValue) 其它常用操作
- 从 SharedPreferences copy数据并清空
mKv.importFromSharedPreferences(context, name) - 获取存储的所有key
mKv.allKeys() - 清理本文件所有值
mKv.clean() - 清除某个数据
mKv.remove(key) - 清除某些数据
mKv.remove(arrKeys)已有数据迁移
考虑兼容现有数据缓存基类 SeriserBean,将现有的 SharedPreferences 使用的封装过的 SeriserBean ,所以想到将 SeriserBean 中的方法提取为接口KvSaveInterface:
public interface KvSaveInterface {
void InitData();
//region String 类型
void putString(String key, String value);
String getString(String key, String value);
//endregion
//region String 加密类型
/**
* 获取解密字符串
*
* @param key
* @param value
* @return
*/
String getStringEncry(String key, String value);
/**
* 放入加密字符串
*
* @param key
* @param value
*/
void putStringEncry(String key, String value);
//endregion
//region Float 类型
void putFloat(String key, float value);
float getFloat(String key, float value);
//endregion
//region Int 类型
void putInt(String key, int value);
int getInt(String key, int value);
//endregion
//region Loong 类型
void putLong(String key, long value);
long getLong(String key, long value);
//endregion
//region Boolean 类型
void putBoolean(String key, boolean value);
boolean getBoolean(String key, boolean value);
//endregion
//region Double类型
void putDouble(String key, double value);
double getDouble(String key, double value);
//endregion
void Clean();
}原来的 SeriserBean 和新的 UuKvBean 共同实现 KvSaveInterface 中的方法;
UuKvBean 初始化时校验 MMKV 是否已完成初始化否则自动进行初始化;
UuKvBean 初始化后自动完成从旧的 SharedPreferences 文件完成数据迁移;
这样在业务侧替换时,只需要将引用 SeriserBean 替换为 UuKvBean 即可,业务侧用户的数据也不会丢失。

成果
用户端本次变更版本在2月16日开始发版审核,2月17日审核通过并发布。
上线一周后,Android客户端发生 ANR 的发生率可以看到有明显下降:

现在新版的跑腿用户端中,业务侧所用到的20个缓存配置文件,SeriserBean 都已换成了新的 UuKvBean,整体表现稳定,未发生数据丢失或反馈相关异常。
思考延展
MMKV 中使用的 protobuf 协议 具有以下几个主要的优点:
1:序列化后体积相比Json和XML很小,适合网络传输
2:支持跨平台多语言
3:消息格式升级和兼容性还不错,支持标准的 IDL
4:序列化/反序列化速度很快,快于Json的处理速速
那么它能给我们带来什么?
问题:请求参数不易维护
请看下面一串文本,这是下单计价的接口的请求数据。
202800,44500,0,郑州市,金水区,民航路12号($)民航路12号附-1号院($),1113.7234833|314.7707303,金水区金水路216号($)广汇·PAMA($)山西刀削面馆,1113.7265735|314.7700335,0|1|1900-01-01|1900-01-01,0,0,0,,,0,0,0,0,15475154585,1544545454,7045,0,0,3,,0,0,郑州市,0,0,0,0,金水区,0,0,0,0,0,票据,0.0,0.0,0.0,0,0如果正在调试这个接口,从以上数据中找出某个参数以查看数据的准确性,看到这44个”,”和一堆0,是不是感觉到很酸爽呢?是的:检查或修改时可读性比较差,维护新增参数只能后面追加,已有的参数即使废弃了还需要“,”继续占位。
优化方向
利用 protobuf 空间开销小、高解析性能的特性,我们网络请求中请求参数的数据组装,可以考虑使用 protobuf 协议的数据来替换,下面是转换为IDL 文件的一段数据文本示例(因为profobuf是二进制数据格式,数据本身不具有可读性需要编码和解码,这是经过解码和反序列化后的内容,实际存储或传输的数据是序列化后所生成的二进制消息非常紧凑):
message Address
{
required string city=1;
optional string postcode=2;
optional string street=3;
}
message UserInfo
{
required string userid=1;
required string name=2;
repeated Address address=3;
}