
背景
近几年,众多企业和机构对于机器学习项目落地愈发重视起来,对业务的理解,模型应用流程等都做的越来越好,也有越来越多的模型被部署到真实的业务场景中。但是当业务真正开始使用的时候,就会对模型有各种各样的需求反馈,算法工程师们就开始不断的迭代开发,频繁部署上线。随着业务的发展,模型应用的场景也越来越多,管理和维护这么多模型系统就成了一个切实的挑战。为解决此问题,大数据团队开始着手探索统一的特征平台。
算法模型的开发
AI 算法模型的开发与落地,大致分为以下三个阶段:
- 数据准备
- 模型训练
- 模型部署
其中,模型训练的本质是大规模数据计算,模型部署则相当于传统软件工程的在线服务部署。特征平台在整个过程中可以起到加速模型训练、简化模型部署流程、提高数据准备效率的作用。
特征平台的目标
对于特征平台的能力与边界,各家定义不尽相同,《Feature Stores – A Hierarchy of Needs》做了很好的总结,大致分为如下几个目标:
特征管理: 特征抽取、处理、存储、元数据管理,以便于特征溯源、分享、复用。
特征消费服务: 为线上部署的模型,提供高吞吐、低延迟的特征获取能力。
离线/在线特征一致性: 避免 Training-Serving Skew 问题导致模型效果劣化。
便利: 易用、简单的交互和 API。
自治: 特征回填、数据质量监控、联动模型效果评估等。
特征平台的典型架构
基于上述目标,实现一个特征平台至少要具备以下几个能力:
- 特征创建从各类原始数据,例如日志、记录、表,经过关联、统计、转化、聚合等操作得到一系列值。
- 特征注册中心通常以 UI 控制台暴露给用户使用,平台上所有特征均在此展示,方便平台用户进行探索、共享、复用。
- 特征离线存储&消费离线存储&消费能力是为模型训练阶段服务的。
- 特征在线存储&消费在线存储&消费能力是为模型部署阶段服务的。
一个典型的架构如下图所示: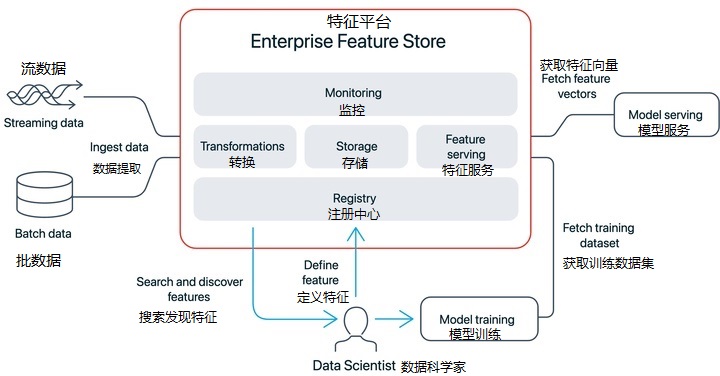
特征平台的初步落地
为了实现适用于我们团队工作流的特征平台,前期调研了业界许多成熟的特征平台,如:美团外卖特征平台、小米广告特征平台、伴鱼机器学习特征系统,以及一些优秀的开源框架如 Feast 等。最终,根据大数据团队自身特点和对特征工程的规划,我们决定以 OpenMLDB 集群版为基础进行特征平台建设。
OpenMLDB
OpenMLDB 是一个开源机器学习数据库,提供企业级 FeatureOps 全栈解决方案
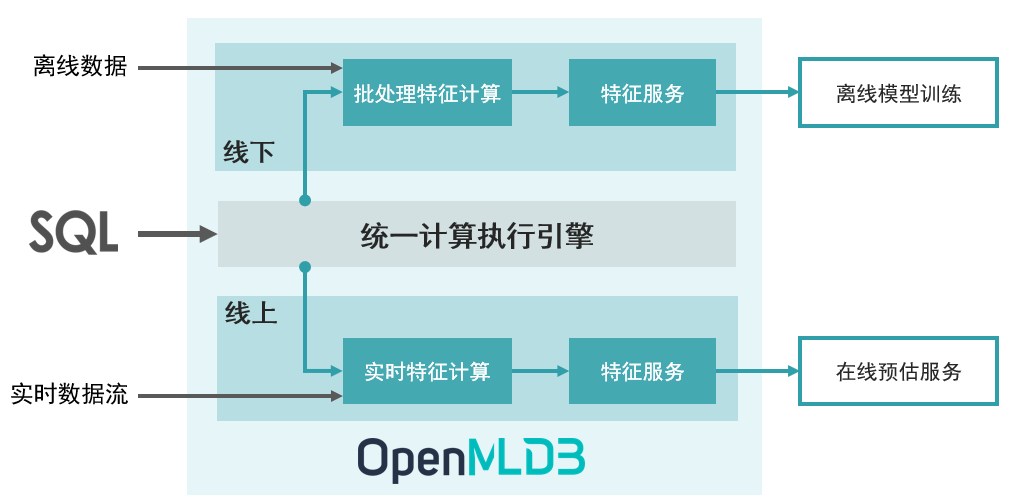
基于 OpenMLDB 使特征开发到上线变得极为简单,只需要三个步骤:
1>. 使用 SQL 进行线下特征计算脚本开发。
2>. SQL 特征计算脚本意见部署上线,由离线模式切换为在线模式。
3>. 接入实时数据流,进行在线实时特征计算和供给服务。
特性
- 线上线下一致性执行引擎
算法模型离线训练得到的 SQL 脚本,一键部署上线,具有统一的底层计算函数,使『线上线下一致性』得到天然保障。 - 毫秒级超低延迟的实时 SQL 引擎
线上实时 SQL 引擎基于完全自研的高性能时序数据库,对于实时特征计算可以达到毫秒级别的延迟 - 面向特征计算的优化的离线计算引擎
多窗口并行计算优化,数据倾斜计算优化,现代化硬件优化技术,针对特征计算优化的 Spark 发行版 - 基于 SQL 定义特征
基于 SQL 进行特征定义和管理,并且针对特征计算,对标准 SQL 进行了增强,引入了诸如LAST JOIN和WINDOW UNION等定制化语法和功能扩充 - 生产级特性
高可用、无缝扩缩容、平滑升级、监控 - 以 SQL 为核心的开发和管理体验
基于 SQL 和 CLI 的全流程开发体验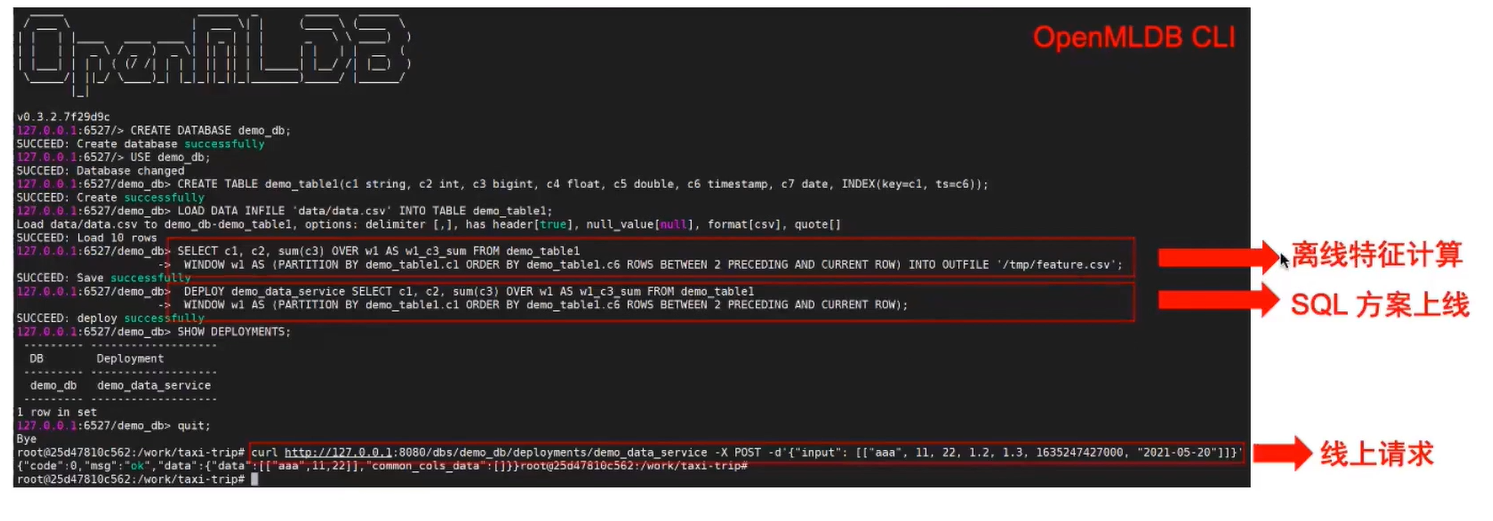
快速上手
一、启动服务端&客户端连接(默认环境为官方 Docker 镜像)
启动集群服务端
./init.sh
启动集群 CLI 客户端
../openmldb/bin/openmldb --zk_cluster=127.0.0.1:2181 --zk_root_path=/openmldb --role=sql_client
二、 创建数据库和表
在上述 CLI 客户端执行:
> CREATE DATABASE demo_db;
> USE demo_db;
> CREATE TABLE demo_table1(c1 string, c2 int, c3 bigint, c4 float, c5 double, c6 timestamp, c7 date);
三、导入离线数据(算法模型训练所需的特征数据)
切换至离线模式
> USE demo_db;
> SET @@execute_mode='offline';
导入准备好的数据文件 data.parquet
> LOAD DATA INFILE 'file:///work/taxi-trip/data/data.parquet' INTO TABLE demo_table1 options(format='parquet', header=true, mode='append');
四、特征抽取
将部分所需特征数据导出至 /tmp/feature_data
> USE demo_db;
> SET @@execute_mode='offline';
> SELECT c1, c2, sum(c3) OVER w1 AS w1_c3_sum FROM demo_table1 WINDOW w1 AS (PARTITION BY demo_table1.c1 ORDER BY demo_table1.c6 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) INTO OUTFILE '/tmp/feature_data';
五、部署上线
离线训练完成,得到 SQL 脚本,执行部署命令
> DEPLOY demo_data_service SELECT c1, c2, sum(c3) OVER w1 AS w1_c3_sum FROM demo_table1 WINDOW w1 AS (PARTITION BY demo_table1.c1 ORDER BY demo_table1.c6 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW);
六、在线数据准备
切换至在线模式
> USE demo_db;
> SET @@execute_mode='online';
导入在线冷启动数据,也可以通过流式数据导入 如 kafka
> LOAD DATA INFILE 'file:///work/taxi-trip/data/data.parquet' INTO TABLE demo_table1 options(format='parquet', header=true, mode='append');
七、实时特征计算
通过 Web API 进行实时特征计算
http://127.0.0.1:9080/dbs/demo_db/deployments/demo_data_service
\___________/ \____/ \_____________/
| | |
APIServer地址 Database名字 Deployment名字
请求示例:
curl http://127.0.0.1:9080/dbs/demo_db/deployments/demo_data_service -X POST -d'{"input": [["aaa", 11, 22, 1.2, 1.3, 1635247427000, "2021-05-20"]]}'
返回结果:
{"code":0,"msg":"ok","data":{"data":[["aaa",11,22]]}}
适用性
除上述演示的 Shell CLI 外, OpenMLDB 还支持 Java SDK、Python SDK。同时具备接入流式数据的能力,兼容 Flink 实时数据流、数据仓库数据流等,可以通过 Kafka Sink Connector 来实现,与大数据团队常用技术栈结合相得益彰。
思考与总结
基于 OpenMLDB 的特征平台,帮我们解决了最大的痛点:离线实时一致性问题,同时还具备大数据量实时特征计算的能力,使特征平台的初步落地变得相对简单。
以 SQL 为核心的开发流程,使特征计算、抽取等极易上手,但在某些复杂场景下,单纯使用 SQL 编写逻辑不好实现,这就需要开发 UDF(用户自定义函数)来解决,以突破原有 SQL 表达能力的限制,目前只能通过 C/C++ 来实现,因此对算法工程师的能力就有了更高的要求。