
1 背景
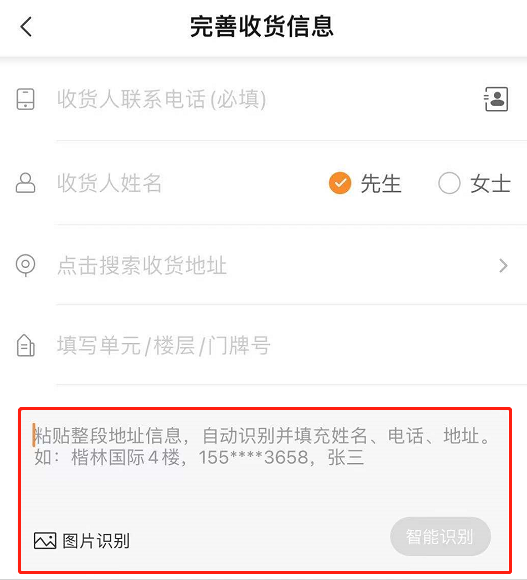
快递服务业在人们的生活中起着越来越重要的作用,寄快递的第一步就是填写寄件人、收件人信息,这些信息包括但不限于姓名、电话号、地址、门牌号等。随着用户越来越“懒”,产品也要越来越“精”,如何从用户粘贴的一段文本中快速、精准地识别出实体信息对用户的产品体验至关重要。
2 数据集
2.1 数据来源
经过多年的业务沉淀,UU跑腿已累积大量经加密的地址文本数据,从数据库中随机抽取20万条数据进行预标注和人工修正,按照8:2划分训练集和测试集。
2.2 标注方法
数据格式如下所示,它的每一行由一个字及其对应的标注组成,标注采用BIO模式进行,即实体的第一个字为B(beginning),其余字为I(inside),非实体字统一标记为O(outside),句子之间用一个空行隔开。

因数据与数据之间是用空行隔开,也就意味着某条数据中是不可以出现空格、回车、制表符等符号,所以需要提前将数据进行预处理,可将所有空格替换为“ˋ”,所有换行符、制表符替换为“|”。
3 模型
3.1 技术迭代
地址解析本质上属命名实体识别(NER)任务,经隐马尔可夫(HMM)、条件随机场(CRF)、卷积神经网络(LSTM)等技术迭代,业界长期默认将LSTM+CRF作为最佳模型,直到称霸自然语言处理(NLP)任务的Bert模型出现,这一局面才被打破。
3.2 Bert+LSTM+CRF
3.2.1 模型结构

3.2.2 未收录词的处理
Bert词典中只收录汉字7321个,虽说已覆盖常用汉字,但与企业数据相比还是会遗漏很多,所以需要对未收录词进行处理。
好在Bert模型已考虑到该情况,预留有添加新词的接口。在实际处理时,为避免噪声干扰,只将字频大于N的汉字添加。将未收录词添加到Bert词典后还未结束,因Bert词典中每个token都由训练好的词向量表示,所以对于新添加的token还需要对其随机初始化词向量。
3.2.3 Tokenizer
采用Bert的Tokenizer进行分词,虽说Bert对中文是基于字符切分的,但是对于英文、数字还是会进行子词切分,会出现类似于“##ing”的情况。

从上面的示例可以看出,经Bert分词后实体的序列会发生变化,所以要进行标签对齐(编码、char_tag -> token_tag);同样,在预测结束后也要根据标签进行解码(token_tag -> char_tag)。
3.2.4 学习率
在训练模型时,需要对Bert进行Fine-Tune。因Bert为强分类器,而LSTM、CRF为弱分类器且对学习率较敏感,若学习率设置相同的话Bert的强势会忽略LSTM、CRF模型的效果,所以要设置学习率分离,且后者学习率一般为前者的50~100倍。
在算法实现中,将Bert的学习率设置为3e-5,LSTM、CRF的学习率为Bert的80倍;在weight_decay参数的设置上,对bias、LayerNorm.bias及LayerNorm.weight参数不设置weight_decay,而将其他参数的weight_decay设置为0.01。
3.2.5 优化器
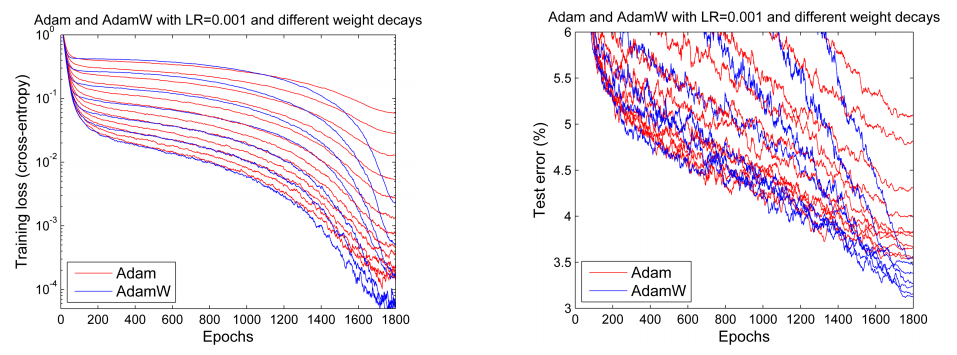
使用AdamW(Adam + weight_decay)作为优化器,AdamW是对传统的Adam + L2 regularization的改进。
3.2.6 Scheduler
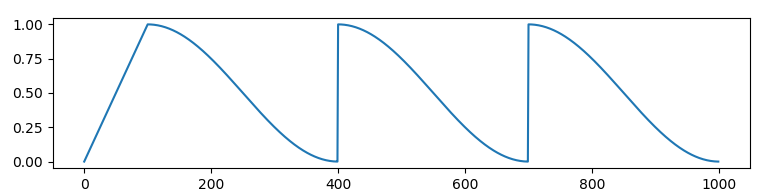
使用cosine_schedule_with_warmup动态调整学习率。
将num_warmup_steps设置为epoch的十分之一,因此学习率会在前十分之一的训练轮次线性递增到设置的学习率数值,在之后余弦下降。
3.2.7 硬件配置 & 训练时长
总训练轮次设置为50个epoch,每个epoch结束后在验证集上计算f1值,并保存最优模型。设置patience_num为10,如果模型在10个连续轮次的训练后验证集结果没有提升则提前终止训练。
在如下表所示配置的服务器训练,每个epoch的耗时为3’8″,总训练平均历时2h。
| 操作系统 | CentOS Linux release 7.5.1804 (Core) |
| CPU | Intel(R) Xeon(R) Gold 6278C CPU @ 2.60GHz * 16 |
| GPU | NVIDIA TESLA T4 16G * 2 |
3.3 模型评估
3.3.1 以实体为粒度的评估指标
以实体为粒度的评估方式较为严格,只有当预测出的实体与标注数据中的实体完全一样时才算做预测正确。以此为标准,相对于原本的线上模型(P=77.5%),精确率提高了14.4%。
事实上,从测试数据错误记录中可以看出,我们的标注数据存在很大的问题,很多数据标注的时候都把空格标成实体,所以此评估指标偏低,实际上的指标要比此值高。
| Label | P | R | F1 |
| ADDR | 0.8691 | 0.8729 | 0.8710 |
| NOTE | 0.8536 | 0.8436 | 0.8493 |
| NAME | 0.9623 | 0.9655 | 0.9639 |
| NUMB | 0.9871 | 0.9893 | 0.9882 |
| AVG | 0.9190 | 0.9192 | 0.9191 |
3.3.2 以char为粒度的评估指标
以char为粒度的评估方式较为松弛,只要每个字的预测结果与标注数据一致就算做预测正确,所以此评估指标较高。真实的评估指标应该介于以实体为粒度与以char为粒度之间。
| Label | P | R | F1 |
| B-ADDR | 0.968 | 0.971 | 0.970 |
| I-ADDR | 0.957 | 0.976 | 0.966 |
| B-NOTE | 0.873 | 0.857 | 0.865 |
| I-NOTE | 0.905 | 0.876 | 0.890 |
| B-NAME | 0.973 | 0.973 | 0.973 |
| I-NAME | 0.969 | 0.962 | 0.966 |
| B-NUMB | 0.989 | 0.992 | 0.991 |
| I-NUMB | 0.992 | 0.967 | 0.964 |
3.3.3 响应时间
分别在CPU和GPU上评估响应时间,多次模拟后取均值。
可以看出,单条数据预测的情况下,CPU的响应时间几乎是GPU的2.5倍,所以在模型部署时优先选择GPU部署。
| CPU | GPU | |
| 响应时间(ms) | 34.5 | 14.9 |
4 总结与展望
不管是在精确率还是响应时间方面,Bert+LSTM+CRF在地址解析任务中都取得不错的结果,但是该模型还有一定的优化空间。
RoBERTa、Whole Word Masking (wwm)都是Bert的升级版本,在国内,哈工大讯飞联合实验室训练有中文模型,且有专门针对NER任务的Bert-wwn、RoBERTa-wwn模型,但是该模型过于庞大,对机器性能要求较高,训练和部署有一定难度,后期可以尝试。
reference
[1] Loshchilov I, Hutter F. Fixing Weight Decay Regularization in Adam[J]. 2017.
[2] The Hugging Face Team. Token Classification with W-NUT Emerging Entities[CP/OL]. https://huggingface.co/transformers/custom_datasets.html#tok-ner. 2021-11.
[3] kmkurn. Pytorch-crf[CP/OL]. https://github.com/kmkurn/pytorch-crf. 2021-11.
[4] brightmart. albert_zh[CP/OL]. https://github.com/brightmart/albert_zh. 2021-11.
[5] ymcui. Chinese-BERT-wwm[CP/OL]. https://github.com/ymcui/Chinese-BERT-wwm. 2021-11.