
1、某日巡检时发现 一服务站点 内存异常
某服务10月15日开始,内存不停增长,CPU的资源占用也增长了不少。
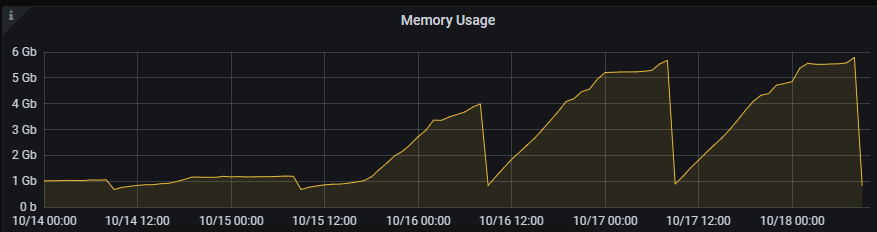
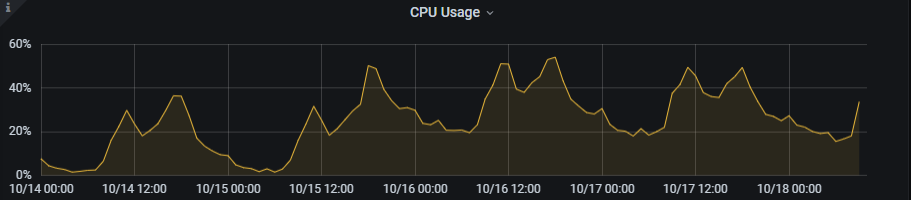
2、排除发布造成的影响
首先怀疑是发布新功能有Bug,但经过排查此服务的最后一次发布10月8日,之后没有再发布过。与运维同学确认了在15日不存在大批量后台统计数据等任务,也没有什么任务变更。
3、内存分析
排除了新代码Bug影响以后,怀疑是有部分接口的代码逻辑有问题,平时流量不大,内存变化不明显。15日时可能有某些业务活动上线造成了流量增大,导致内存增涨。
通过运维拉取了2次(2G\4G)内存镜像,通过分析定位问题。
2G内存镜像,其中2代GC就占用了900多MB
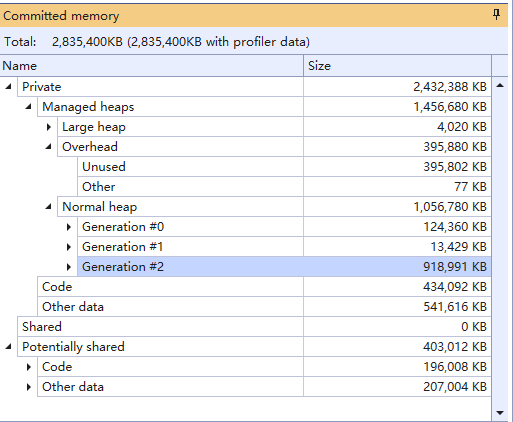
2代GC内存中,按类型聚合后的实例数量和内存占用量

逐个分析实例的引用关系,确定源头。
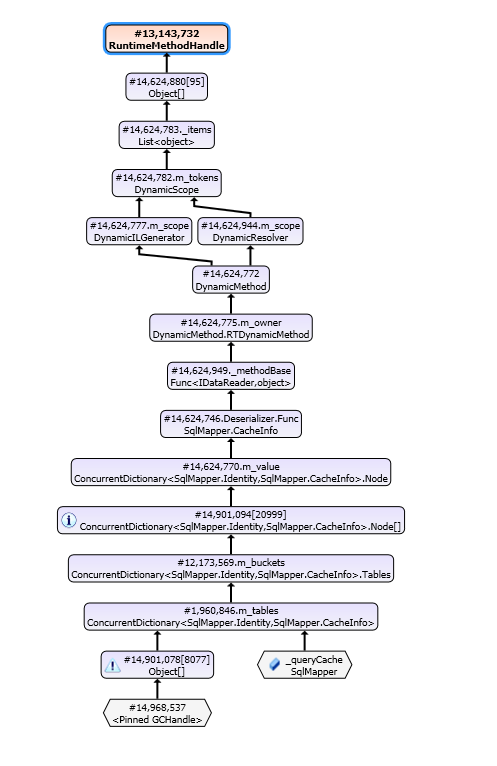
发现可疑的源头,SqlMapper 中的字典
通过查看底层代码,发现SqlMapper中为了提高实体映射效率,添加了一个字典用来缓存sql的实体映射模型。

生成 Identity 的方式如上图。
在此方向上继续排除,定位代码位置
找到字典中Key的位置,确定其中sql的具体内容

这里sql显示的不完整,无法确定查询语句和代码位置。
使用其他工具,追踪此内存内容
在WinDgb中查询此地址的数据 !DumpObj /d 0x250f75904f8
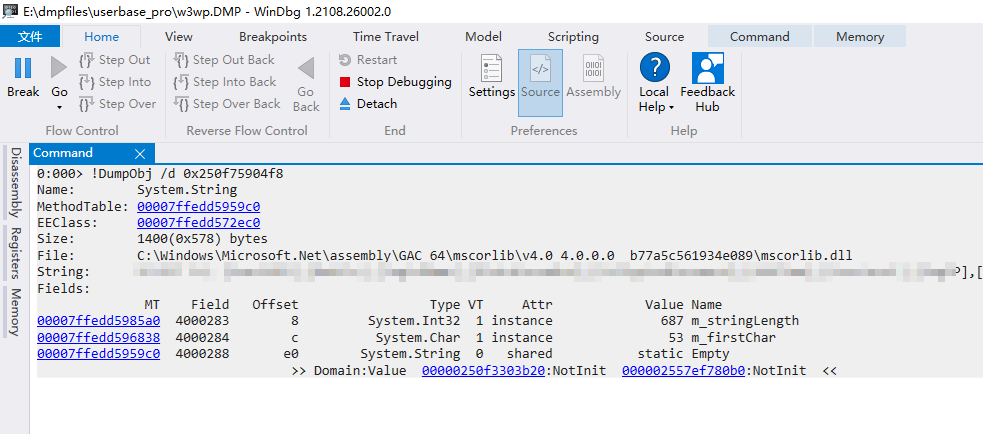
获取到完整的sql内容,根据sql查找业务代码。
4、解决问题
将原来拼sql的方式改为参数化调用。
本地测试,在高频调用此接口后,确实会出现内存的泄漏风险,修改为参数化后内存使用正常。

5、排查原因
问题解决了,但到底是什么业务导致了内存从不到1G增长到6G。
找运维同学拉请求日志,通过请求日志分析,确实有一个接口的请求流量在 16日时比之前增长了约20倍。
继续排查,发现MongoDB从15号开始出现了比较高的ops跟内存增高的时间比较一致。根据MongoDB库和调用的接口进行排查,最终确定调用源头。
6、总结
代码中原来存在内存泄漏风险概率,但因为接口流量不大,并且每日内存回收,一直没有显现。10月15日18点开始某业务对此接口的调用频次剧增,最终导致了内存泄漏。