
背景
预计送达时间(Estimated Time of Arrival, ETA)即用户下单后,骑手在多长时间内可将货物送达到用户手中。该时间既可在用户端、骑手端、商户端展示,也可以在智能派单系统中为派单作参考。
在即时配送行业,ETA存在以下难点:
- 无法获取关键信息:ETA在用户(商户)下单时刻就需要被展现,此时订单并未被骑手接单,因此无法提前获取骑手的信息及其实际的配送路径;
- 需要考虑更多影响因素:一般的ETA问题仅需考虑天气、交通状况、时空信息及路径信息等,而即时配送中ETA除了考虑此类信息外,还需考虑商户的地理位置,商户的实时动态以及调度系统派单等信息;
- 配送系统的调节中枢:需要平衡用户-骑手-商家-配送效率之间的关系;
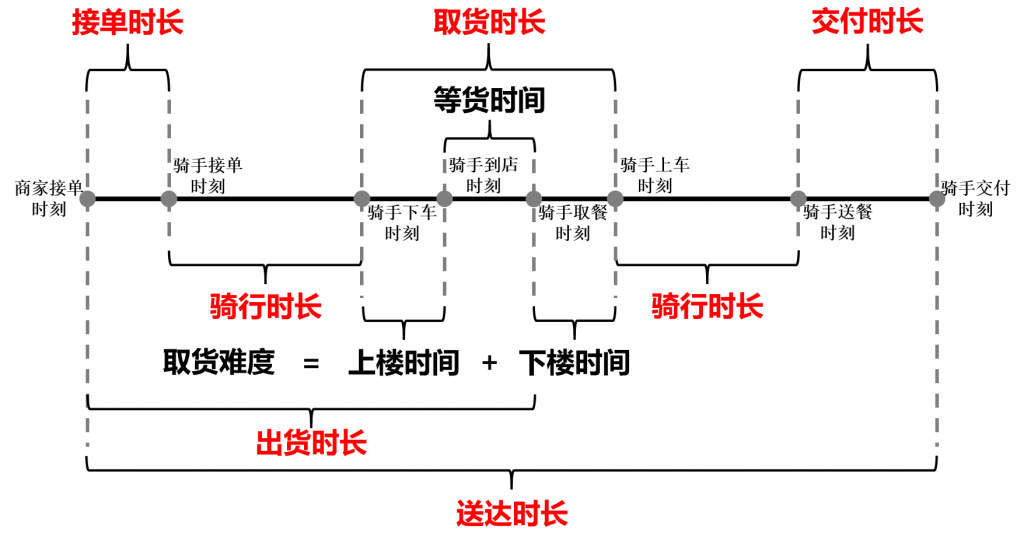
站在骑手的角度看,可以将ETA抽象为以上这幅图。图中将依据骑手的具体动态将全程ETA拆分为接单时长、骑行时长、取货时长、骑行时长和交付时长等五个阶段。
- 接单时长:主要与用户(商户)下单时刻该区域运力平均水平、骑手规模等因素相关;
- 骑行时长:主要与取货距离、路况、环境、天气、早晚高峰时刻等因素相关;
- 取货时长:主要与商户画像(地址、经纬度、品类、平均取货时长等)、商户实时特征(出单量、进单量、挤压状况等)、订单特征、早晚高峰时刻等因素相关;
- 骑行时长:主要与送货距离、路况、环境、天气、早晚高峰时刻等因素相关;
- 交付时长:主要与用户画像(地址、经纬度、楼层、是否有电梯等)、早晚高峰时刻等因素相关;
在以上五个阶段中,接单时长以及两段骑行时长基本上与用户、商户、订单等无关,更多的是与区域运力、路况、环境、天气等因素相关;而取货时长、交付时长则主要与用户、商户、订单等相关,所以以此为突破口进行实践。
特征 & 模型 & 评估
特征工程
离线特征
- 配送区域画像:城市id、区域id、区域运力平均水平、骑手规模、单量规模、平均配送距离等;
- 商户画像:商户POI信息(id、店名、品类、地址、经纬度、标签)、平均接单/出货/到店/取货/送达时长、平均配送距离、出餐状况、单量、品类偏好、客单价等;
- 用户画像:用户id、交付地址、交付经纬度、楼层、是否有电梯等;
在线特征
- 配送区域实时特征:在岗骑手实时规模、区域挤压(未取货)单量、运力负载状况等;
- 商户实时特征:过去N分钟出单量、过去N分钟进单量、过去N分钟订单挤压状况、过去N分钟平均接单/出货/到店/取货/送达时长;
- 订单特征:价格、品类、数量、时段、是否周末、配送距离等;
- 环境特征:天气、温度、降水、风量等;
模型迭代
在模型建立之初,应该明确一点,即ETA预估属回归问题,即根据多维度特征预测出某个具体数值。
结合以上特征不难发现,离线特征中存在大量id类特征,如城市id、区域id、商户id、用户id等,所以模型需能解决高维稀疏特征的处理;同时模型不能过于复杂,因ETA预估属基础服务,对计算性能要求较高。
LR(Linear Regression)
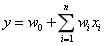
逻辑回归是最基础的回归模型,在项目刚启动时作为baseline。
从逻辑回归的公式可以看出,该模型将每个特征训练一个参数,笔者最开始只考虑了“时段”、“是否周末”、“物品类型”三个特征作实验。研究发现,逻辑回归通常会将“时段”拟合出一条曲线,该曲线往往与整体的平均取货时间重合(想一想为什么?),而“是否周末”、“物品类型”的改变只会影响曲线的整体上移或下移。这明显是不符合常理的,但也说明了逻辑回归的缺陷:特征之间独立!
事实上,大量特征之间是有关联的。为了解决特征独立问题,可以使用特征组合(多项式),即将特征与特征之间进行交叉。
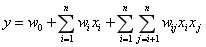
但对于离散特征来讲,通常在模型训练之前会进行One-Hot编码,编码后的向量非常稀疏。如上式所示,若直接进行特征交叉(多项式)则特征维度会异常之大,时间复杂度也为O(kn^2),非常不利于模型训练。于是,Steffen Rendle于2010年提出FM(Factorization Machines)模型,目的是为了解决稀疏数据下的特征组合问题。
FM(Factorization Machines)

LR主要引入矩阵分解的思想求解特征交叉项的权重,时间复杂度从O(kn^2)降到O(kn)。具体细节在此不再展开,通俗来讲,FM是在LR的基础上增加了二阶(或更高阶)的特征交叉,且时间复杂度还保持线性。
paper: https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
根据paper描述,FM有以下三个优点:
- 可以在非常稀疏的数据中进行合理的参数估计;
- 模型的时间复杂度是线性的;
- 作为一个通用模型,其训练数据的特征取值可以是任意实数;
FFM(Field-aware Factorization Machine)
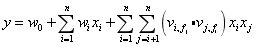
FFM作为FM的升级版,与FM相比主要引入了field概念,FFM把相同性质的特征归于同一field。
在FFM中,每一维特征,针对其它特征的每一种field,都会学习一个隐向量。因此,隐向量不仅与特征相关,也与field相关。需要注意的是,FFM的特征交叉项并不能够简化,时间复杂度为O(kn^2)。
paper: https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf
DeepFM
目前在CTR或ETA领域的预估,最重要的是学习到行为背后的特征组合。在不同的场景下,低阶特征组合和高阶特征组合都可能会对最终的预估结果产生影响。
人工方式的特征工程,通常面临两个问题:特征爆炸和特征之间如何组合。针对这两个问题,广度模型和深度模型提供了不同的解决思路。其中广度模型(LR、FM、FFM)通过对特征的低秩展开,为每个特征构建隐式向量,并通过隐式向量的点乘结果来建模两个特征的组合关系进而实现对二阶特征组合的自动学习;而深度模型(FNN、Wide&Deep)通过神经网络结构和非线性激活函数,自动学习特征之间复杂的组合关系。
但目前广度模型和深度模型都有各自的局限,广度模型一般只能学习1阶和2阶的特征组合;而深度模型一般学习的事高阶特征组合。DeepFM模型结合了广度和深度模型的优点,联合训练FM模型和DNN模型,特征Embedding化后,在FM基础上加入deep部分,分别针对稀疏特征及稠密特征做融合;FM部分通过隐变量内积方式考虑一阶及二阶的特征融合,DNN部分通过Feed-Forward学习高阶特征融合。
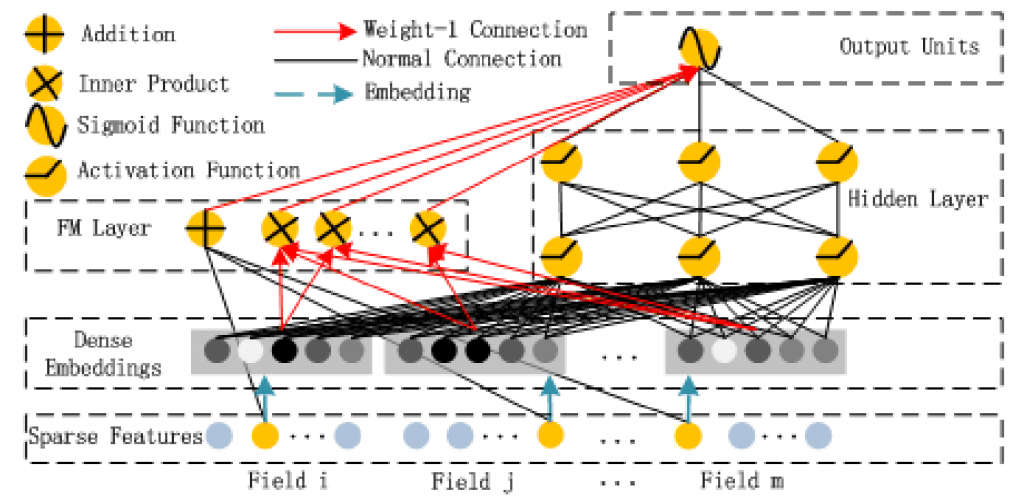
DeepFM相对于现有的广度模型、深度模型来讲,其优势在于:
- DeepFM模型同时对低阶特征组合和高阶特征组合建模,从而能够学习到各阶特征之间的组合关系;
- DeepFM模型是一个端到端的模型,不需要任何的人工特征工程;
paper: https://arxiv.org/pdf/1703.04247.pdf
评估方法
- N分钟准确率:实际送达时长与预估时长的绝对误差在N分钟内的概率;
- N分钟业务准时率:实际送达时长与预估时长的差值在N分钟内的概率;
若干问题及解决方法
如何合理利用骑手信息
骑手对每个区域的熟悉程度不同,将城市划分成以“网格”为最小单元的不同区域。
ETA在用户下单时刻就需要被展现,此时订单指派给具体哪位骑手是未知的。为充分利用与骑手相关的影响因素,会根据骑手取餐距离、骑手当前身上的订单数等特征表征每一位可能接单的骑手,然后将骑手序列进行特征编码传入外卖ETA模型中,随后利用注意力机制提取骑手序列信息,以此来增强模型的预测能力。
后处理
虽然训练数据已经做了数据清洗,但难免会存在一些异常订单,而这些异常订单会影响整体模型的效果,具体表现为所预估的取货时长为负值或者为2小时以上的异常值,所以需要对预估的取货时长进行后处理。
后处理的具体做法是使用该商户的平均取货时长进行缩放,进行最大最小值的限制(最小值通常为0,最大值通常为平均取货时长的3倍)。当所预估的取货时长为负值时就取最小值,当所预估的取货时长为较大的异常值时,就取最大值。
长尾问题
- 业务长尾:整体样本分布造成的长尾;主要体现在距离、价格等维度;距离越远,价格越高,实际送达时间越长,但样本占比越少;
- 模型长尾:由于模型自身对预估值的不确定性造成的长尾;模型学习的是整体的统计分布,但不是对每个样本的预估都有“信心”;可采用多棵决策树输出的标准差衡量不确定性;
预估效果展示
某餐饮店
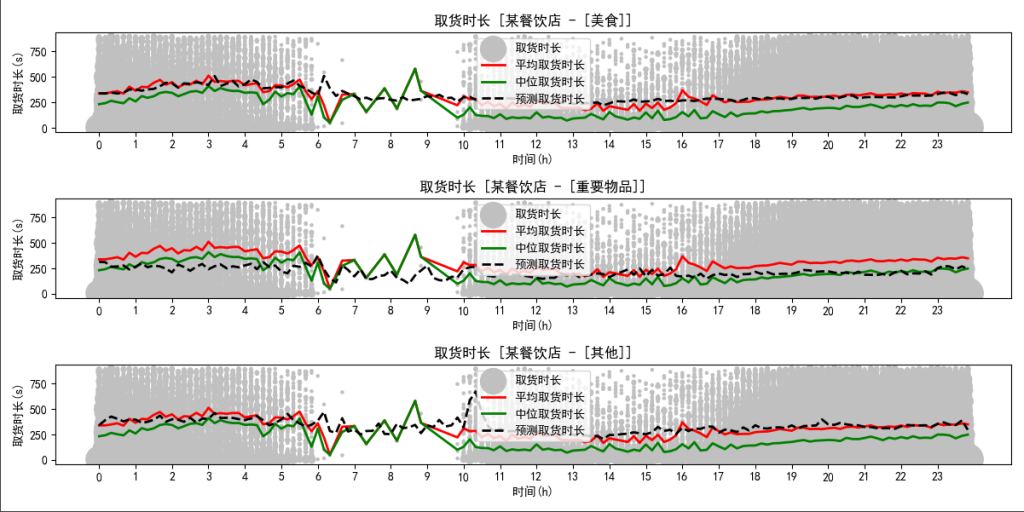
上图是某餐饮店分别针对“美食”、“重要物品”、“其他”等三种物品类型所作出的取货时长预估。
从中可以看出,“美食”、“其他”两种类型基本与该商户的平均取货时长持平,而“重要物品”类型相较于平均取货时长则大幅度降低。究其原因也不难解释,因其为餐饮店,故“美食”等货时间较久;而“重要物品”往往是手机、钥匙、证件等,不需过长等待;再者,“其他”中往往包含各种各样的无标签物品,与平均取货时长持平也可理解。
某宠物店
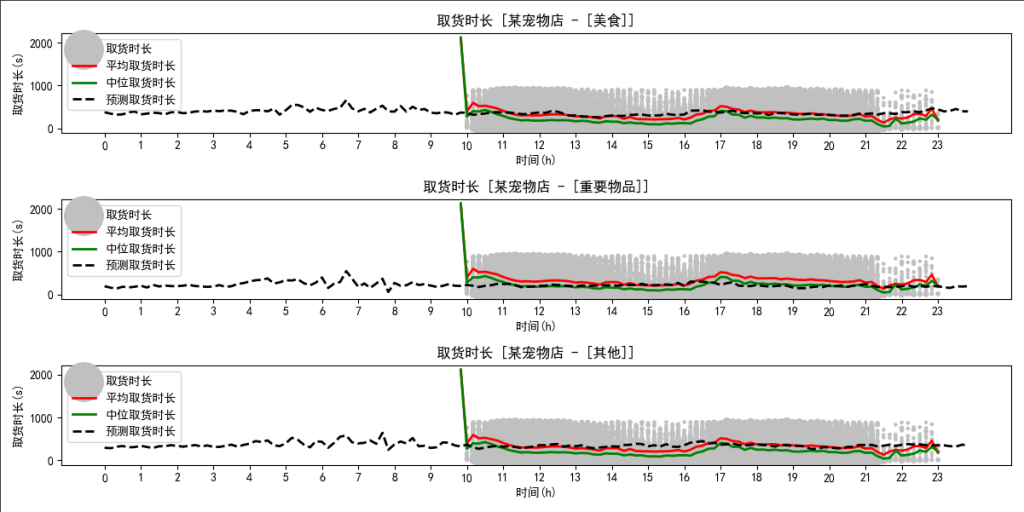
同样是针对“美食”、“重要物品”、“其他”等三种物品类型所作出的取货时长预估,不同的是上图针对的是某宠物店,主要是为了与某餐饮店做对比。
从中可以看出,三种类型的取货时长预估结果类似,并没有像某餐饮店似的有大幅度变化。其原因也很容易解释,因其为宠物店,发布“美食”的订单几乎为0,更多的是“重要物品”或“其他”,那么为什么“美食”类型预估的结果与其他两种类似呢?因为若该类型的订单(训练数据)较少的话,模型就会学习整体的平均水平。这种现象在上图的0~10点区间更能说明,宠物店往往只有白天营业,那么晚上的订单(训练数据)几乎没有,若偶尔出现一个深夜订单难道模型就没办法预测了吗?很明显不是的,模型会结合多特征维度学习整体的平均水平。
模型部署
使用Django框架进行部署,url地址ip:port/predict/,采用post方式访问接口,request和response字段说明如下所示。
request
| 名称 | 类型 | 说明 |
|---|---|---|
| orders | dict | 需要预估的订单信息,key为订单id,value为订单信息,其类型也为dict,包括user_id、city_id、publish_time、goods_type、distance |
| default_value | float | 现阶段模型暂不支持冷启动,若所预估user_id不存在于模型中,则返回此默认值 |
| 名称 | 类型 | 说明 |
|---|---|---|
| user_id | int | 该订单所对应的用户id |
| city_id | int | 该订单所对应的城市id |
| publish_time | str | 该订单的发布时间,形如yyyy-mm-dd hh:mm:ss |
| goods_type | str | 该订单的物品类型 |
| distance | int | 该订单的取货距离,即骑手到商户的距离 |
response
| 名称 | 类型 | 说明 |
|---|---|---|
| code | int | 返回码。200:成功;300/301/302/303/400:失败 |
| msg | str | 返回消息 |
| ret | dict | 预估结果,key为订单id,value为订单信息,其类型也为dict,包括code、msg、pickup_duration |
| 名称 | 类型 | 说明 |
|---|---|---|
| code | int | 返回码。200:成功;201:默认值;300/301:失败 |
| msg | str | 返回消息 |
| pickup_duration | float | 预估取货时长 |
思考和展望
万事开头难,目前针对预计送达时间的预估只做了五阶段中的其一,且该预估实践算是UU跑腿使用人工智能技术在ETA领域迈出的第一步,虽已上线使用,但还存在很多不足,例如考虑特征不全面、冷启动问题等,故在今后的工作中,将围绕以下三方面重点展开:
- 继续优化骑手取货时长,重点放在特征工程方面,可以使用商户特征训练embedding以解决冷启动问题,加入商户地址、坐标等POI信息;
- 借鉴取货时长模型策略,适当调整特征和模型,解决交付时长的预估;
- 探索接单时长、骑行时长的预估算法;
参考资料
- https://mp.weixin.qq.com/s/qyegF_r_SPGnkEdZqkVjxA
- https://mp.weixin.qq.com/s/LgXP2IRbyidRSSH9U7q5RQ
- https://zhuanlan.zhihu.com/p/146916779
- https://zhuanlan.zhihu.com/p/261985122
- https://www.zhihu.com/question/496861462
- https://tech.meituan.com/2019/02/21/meituan-delivery-eta-estimation-in-the-practice-of-deep-learning.html
- https://tech.meituan.com/2017/11/24/gbdt.html
- https://mp.weixin.qq.com/s/Mes1RqIOdp48CMw4pXTwXw