
1 背景
国家互联网产业的飞速发展,方便了数以亿计的国民的生活,国民足不出户翻翻手机就能搜索周边好吃的好玩的,这得益于移动互联网技术的日趋成熟,同时也与我们手机中的GPS定位模块息息相关。GPS(Global Positioning System)是一种全方位、全天候、全时段的卫星导航系统,可以在全球范围内为用户提供定位和导航的服务,被广泛应用于定位服务及车辆导航服务中。但由于GPS定位易受到外界因素的干扰,使得定位精度不太准确,从而出现定位点漂移的情况。在汽车导航系统中,通常采用航向角推算、差分分析等技术以提高定位精度,但这些技术的实现成本较高。由于当前项目中需要解决的是跑男智能手机定位点漂移的问题,故需要从当前业务场景、现有数据出发,实现实时监测跑男定位点,过滤异常定位点坐标功能,从而进一步提升平台自动派单算法的派单质量。因此,针对本项目的实际需求,本文实现了一种基于最大最小距离算法的跑男GPS异常点实时监测技术。
2 算法基本思想
在分析了该项目业务场景的基础上,设计出两种解决跑男定位点漂移的检测方法:一是使用GIS技术,获取跑男当前所在城市的路网数据,采用地图匹配算法,将跑男所经过的定位点数据匹配到最符合条件的道路上,然后基于该道路,识别当前跑男定位点是否存在严重的漂移。二是本文所采用的基于聚类算法的实时监测技术。之所以选择第二种技术方案,主要有以下两点考虑:
(1)方案一需要提前加载路网数据。道路匹配算法计算过程中会消耗大量的计算资源。方案二则是基于当前跑男的历史定位点来实时监测异常定位点,计算量较小。
(2)方案一只能达到准实时的水平。为了能够根据道路拓扑结构匹配到更合适的道路,算法需要分批次的定位点数据来绑定最佳的道路,尤其在道路结构复杂的情况下,每批次的坐标点数越多,越容易匹配到更准确的道路,识别异常坐标的准确度也越高。但每个批次的定位点数越多,其实时性就越难保证。而方案二,只需在冷启动时缓存少量的坐标点即可支撑算法较好的运行,能够达到实时分析的水平。
基于以上两点主要原因,本项目采用方案二来实施。方案二算法的基本思想为:实时获取跑男当前时刻定位点坐标,并缓存当前时刻之前的最新的n条坐标数据,采用最大最小距离聚类算法对缓存的n条坐标点数据进行聚类,计算各聚类簇中坐标点的个数,选取坐标点个数最多的簇计算当前簇的中心点,并从该簇中选取时间戳最大的点作为基准坐标点,而后基于该基准坐标生成以固定速度*两坐标点时间间隔的值为缓冲区半径的圆面,并通过GIS中的拓扑关系判断新产生的坐标点是否在圆面范围内,如果在范围内,则判定当前坐标点为非异常点,否则将该点判定为待测异常点;然后将待测异常点连同缓存的最新的n条坐标数据做最大最小距离的聚类处理,得到新的聚类中心,并以该聚类中心点与待测异常点做上一步中的拓扑结构判定,如果此时待测异常点在圆面范围则判定为正常点,否则判定该点为异常点。
3 算法实现
3.1 最大最小距离算法
最大最小距离算法的主要思想是先选取一个点作为聚类中心,而后根据距离阈值搜索数据集中新的聚类中心,在完成聚类中心的检索后,根据最大相似性原则,将数据集中的数据划分到相应聚类簇中,其具体步骤为:
步骤1:从数据集 中选择一个样本点作为第一个聚类中心,表示为
中选择一个样本点作为第一个聚类中心,表示为 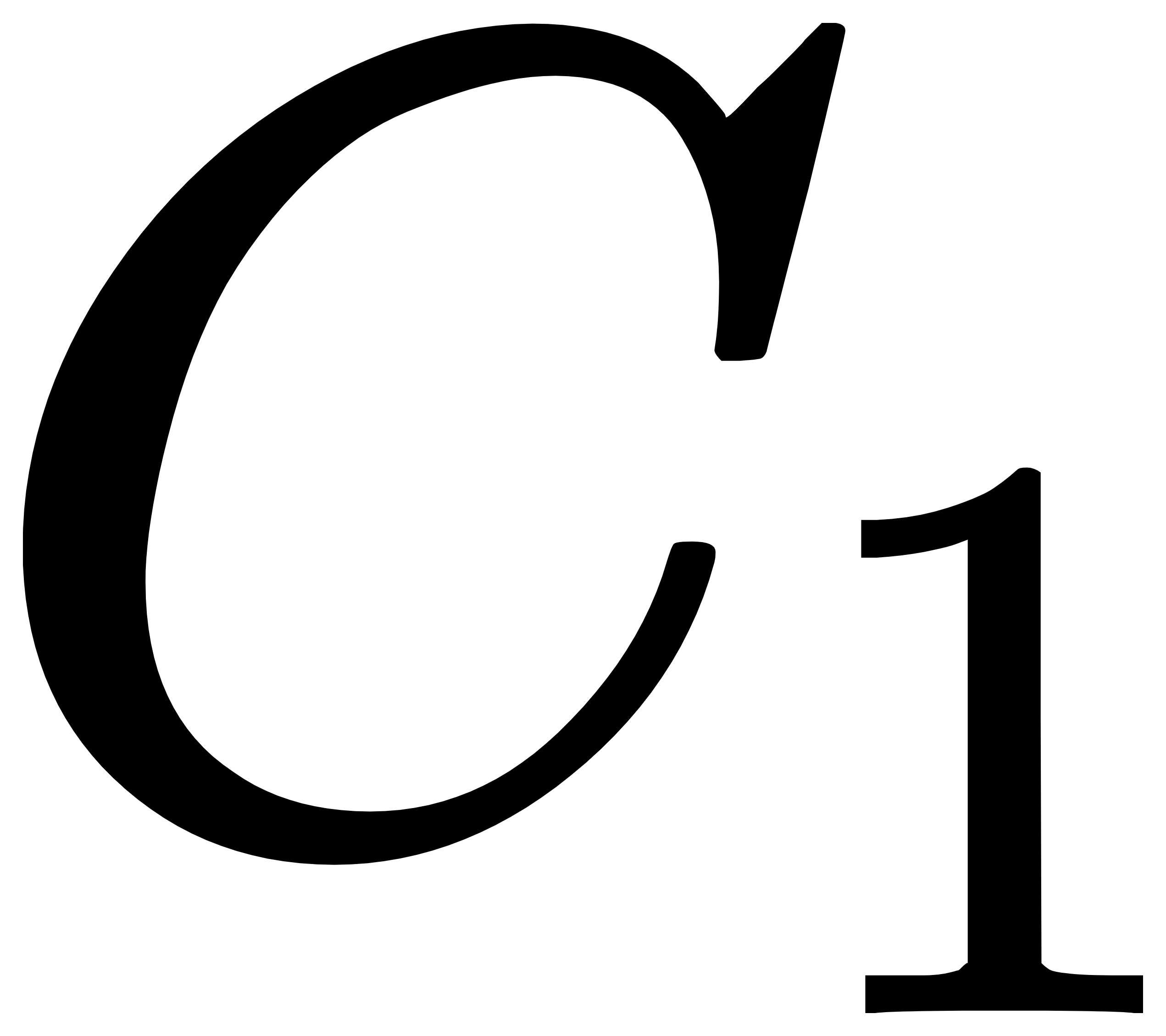 ;
;
步骤2:计算数据集 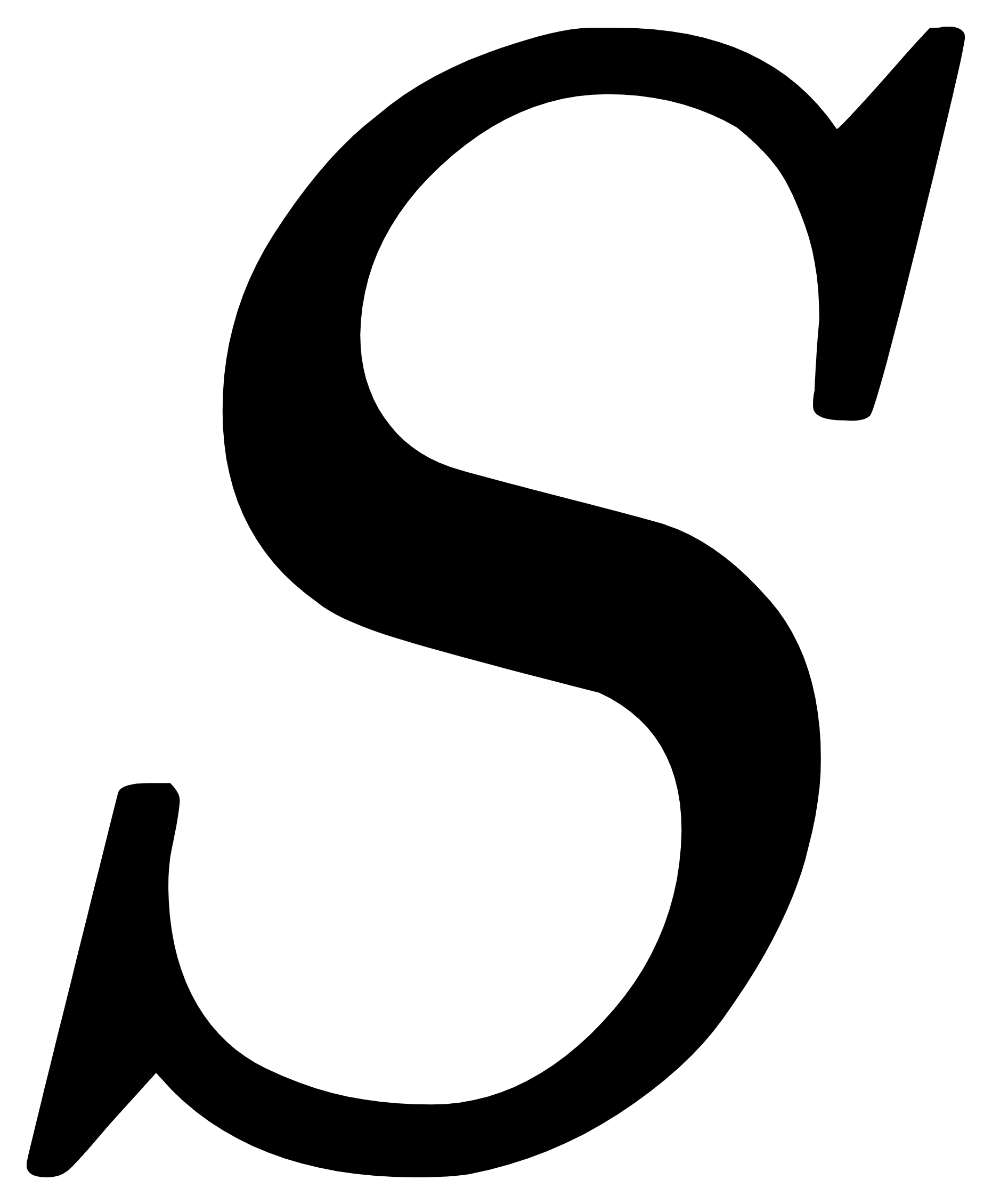 中未被标记为聚类中心的点
中未被标记为聚类中心的点  与第一个聚类中心点 的距离,表示为
与第一个聚类中心点 的距离,表示为  ,选取距离 最远的样本点作为第二个聚类中心点
,选取距离 最远的样本点作为第二个聚类中心点 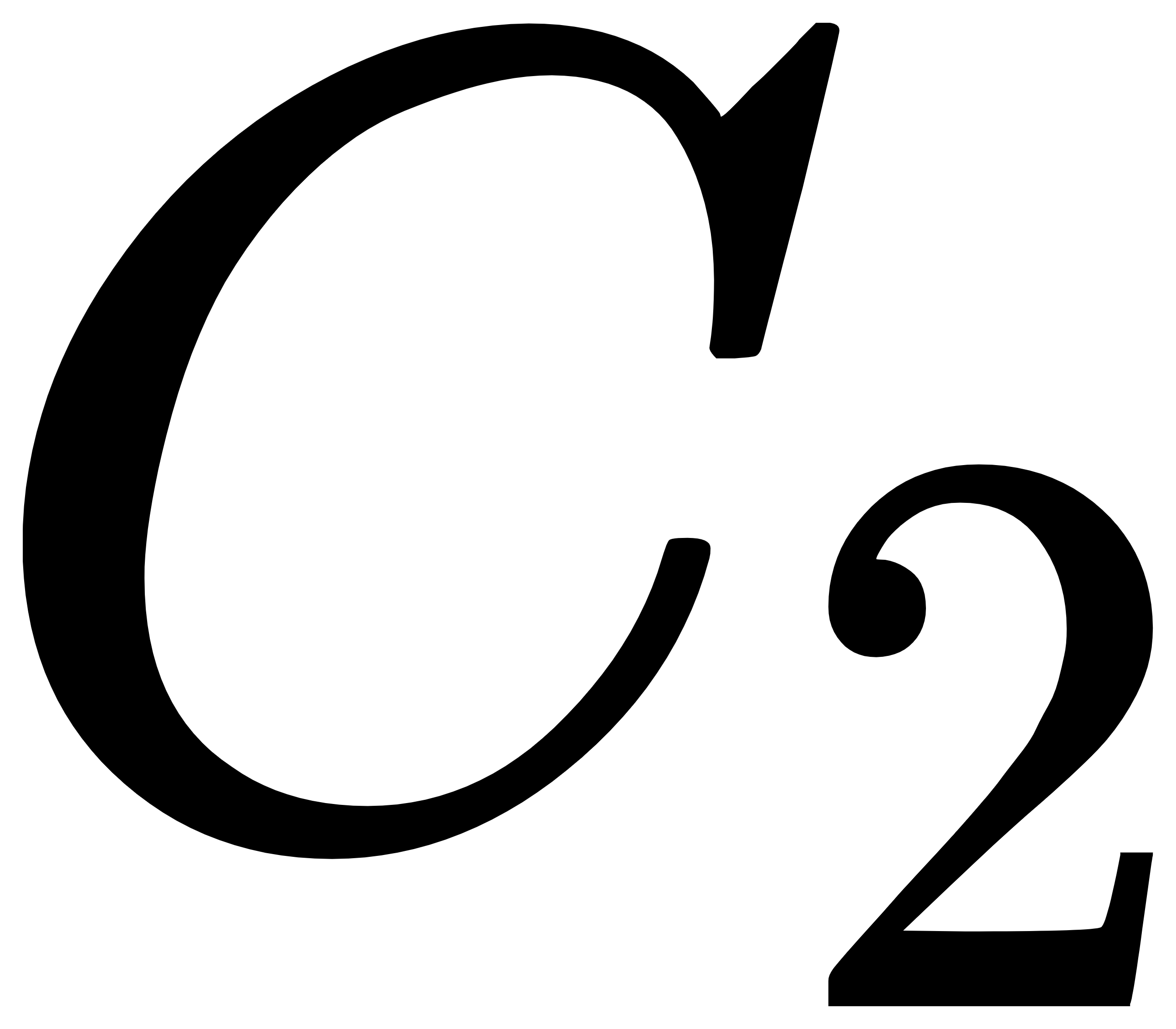 ,即
,即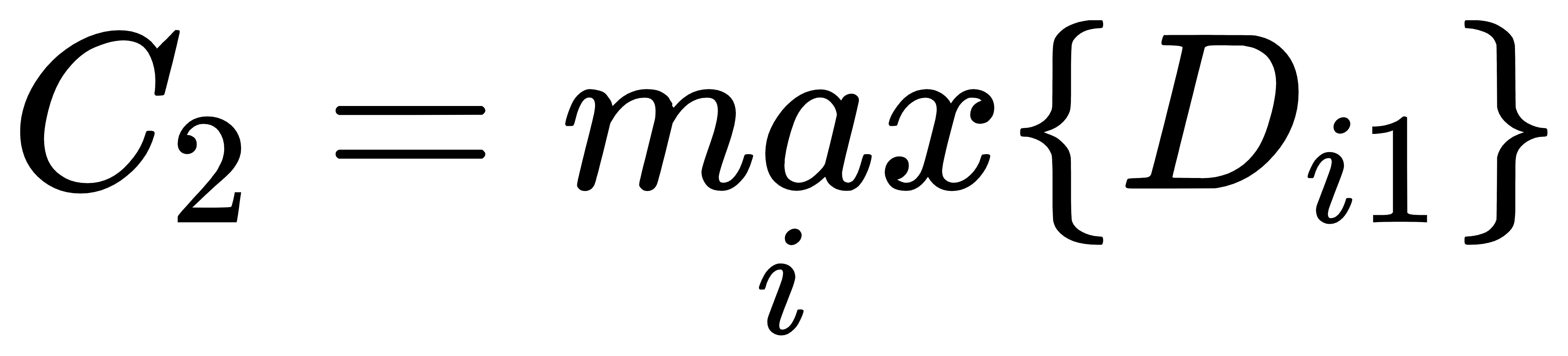 ;
;
步骤3:计算数据集 中未被标记为聚类中心的点 与各聚类中心 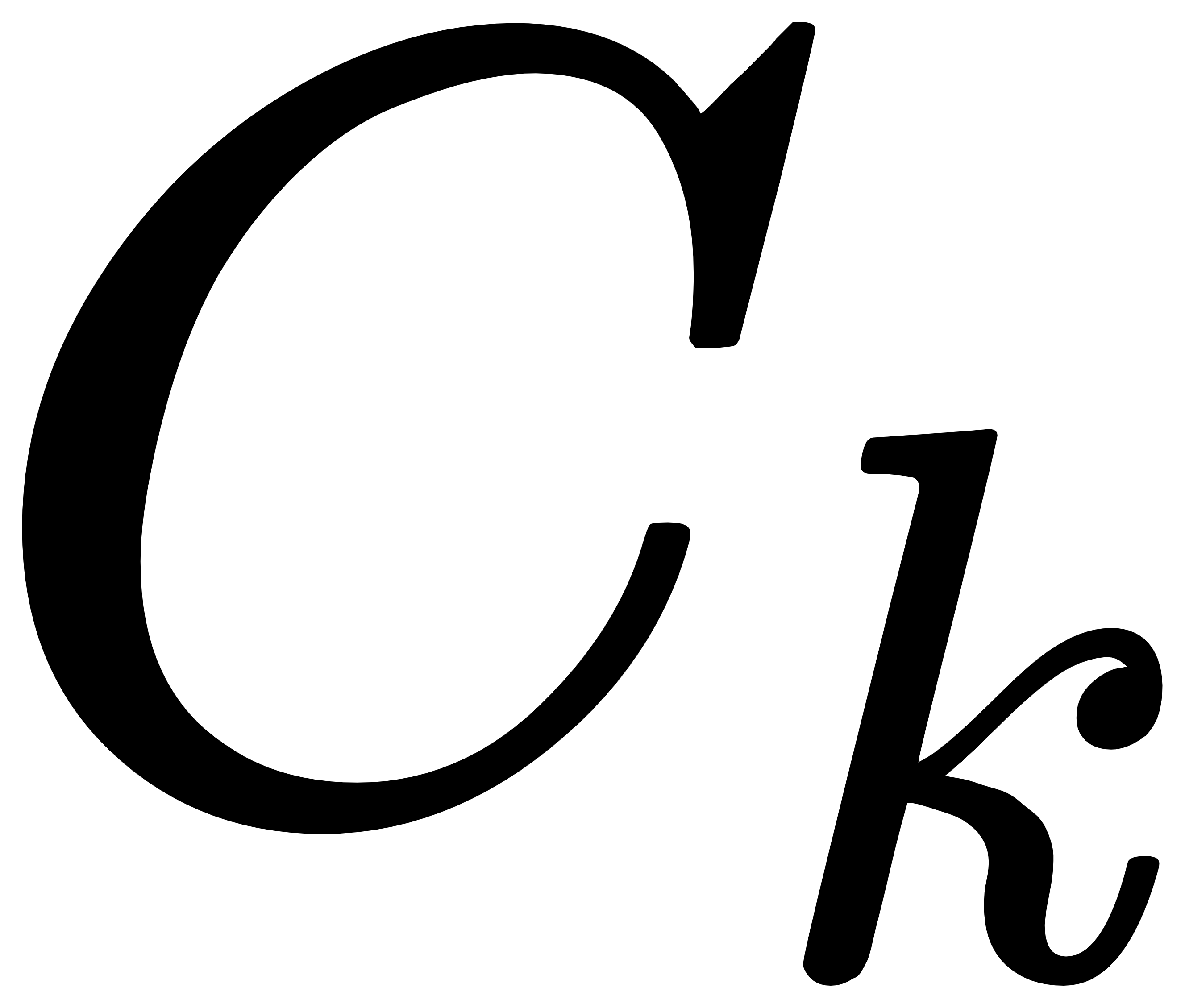 的距离,并计算出 到各聚类中心 的最小值,即
的距离,并计算出 到各聚类中心 的最小值,即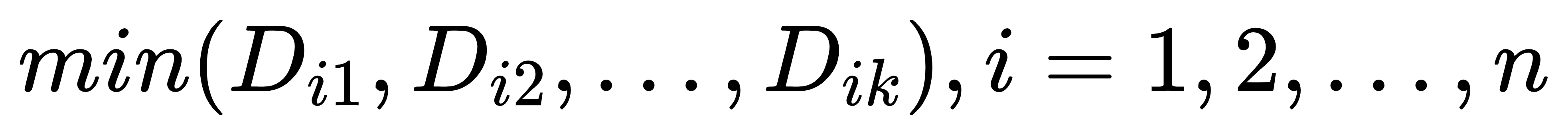 ;
;
步骤4:在步骤3计算出的最小距离集合中找出距离最大值 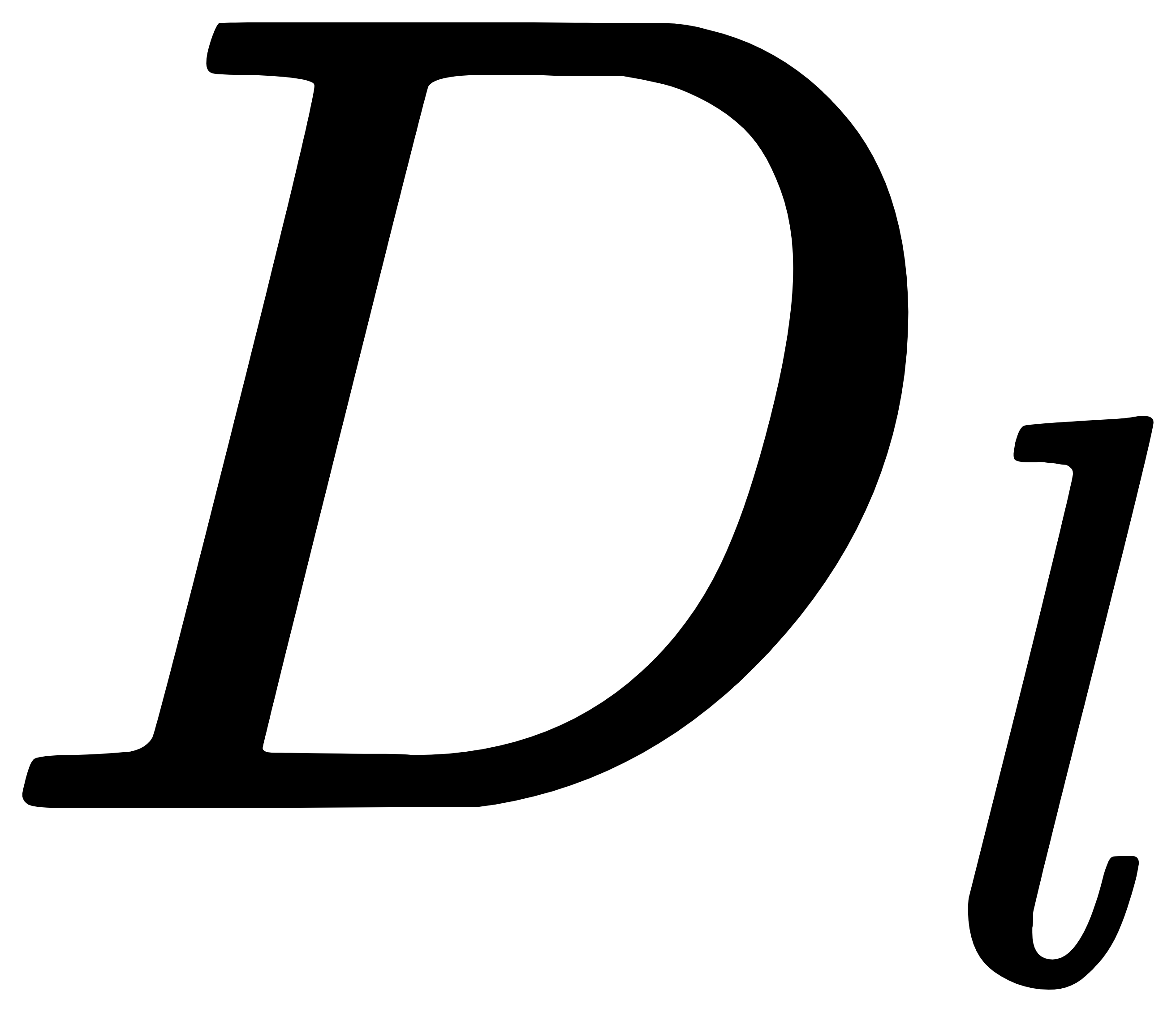 ,如果距离最大值 大于第一个聚类中心与第二个聚类中心之间距离的
,如果距离最大值 大于第一个聚类中心与第二个聚类中心之间距离的 倍,用公式可表述为:
倍,用公式可表述为:

则将距离最大值对应的点作为新的聚类中心,并转至步骤3,否则,转至步骤5,其中 为设定的比例系数;
步骤5:当数据集 中不存在新的聚类中心时,则按照最大相似性原则将数据集 中未标记为聚类中心的点划分到相应的类簇中。
为便于算法的理解,这里使用10个二维坐标点,并选取(0,0)点为第一个聚类中心,设定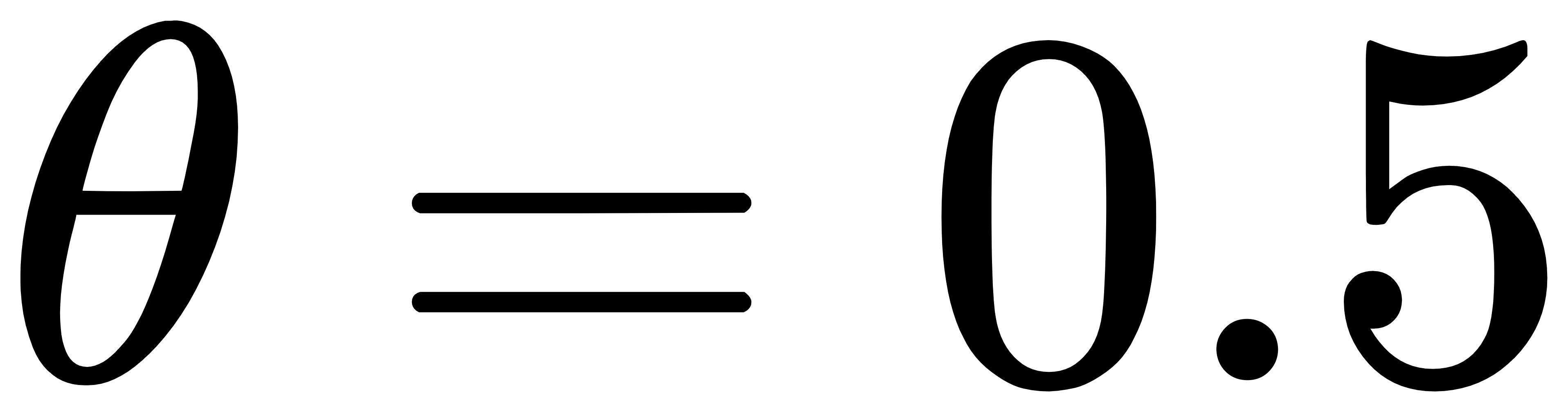 ,执行最大最小距离算法,然后可视化聚类结果,其聚类结果如图1所示。
,执行最大最小距离算法,然后可视化聚类结果,其聚类结果如图1所示。
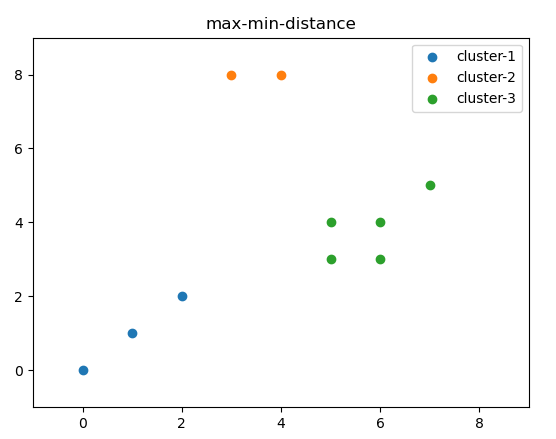
图1 最大最小距离算法聚类结果
3.2 跑男GPS异常点实时监测算法
为了更清晰的描述算法,现给出如下定义:
(1)跑男当前时刻坐标点:实时监测过程中传入系统待监测的跑男坐标点称为跑男当前时刻坐标点,表示为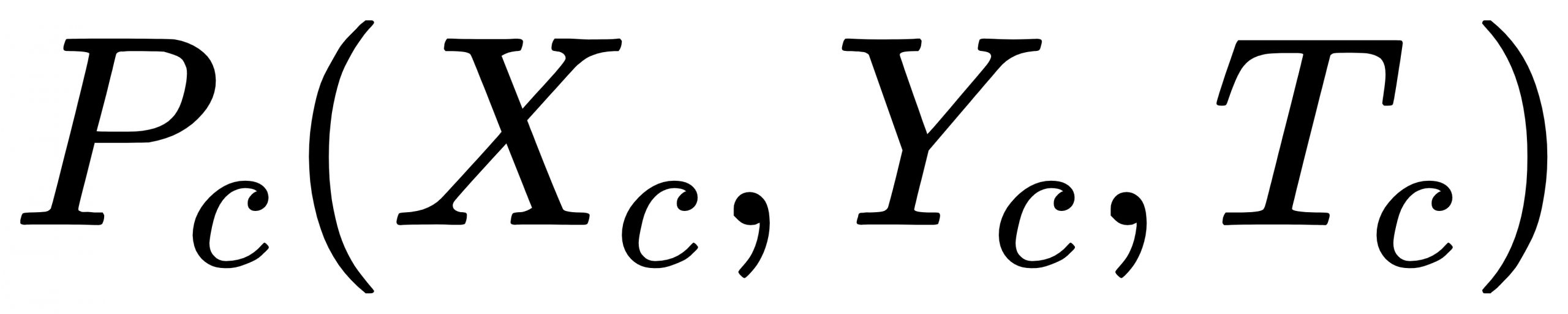 ,其中
,其中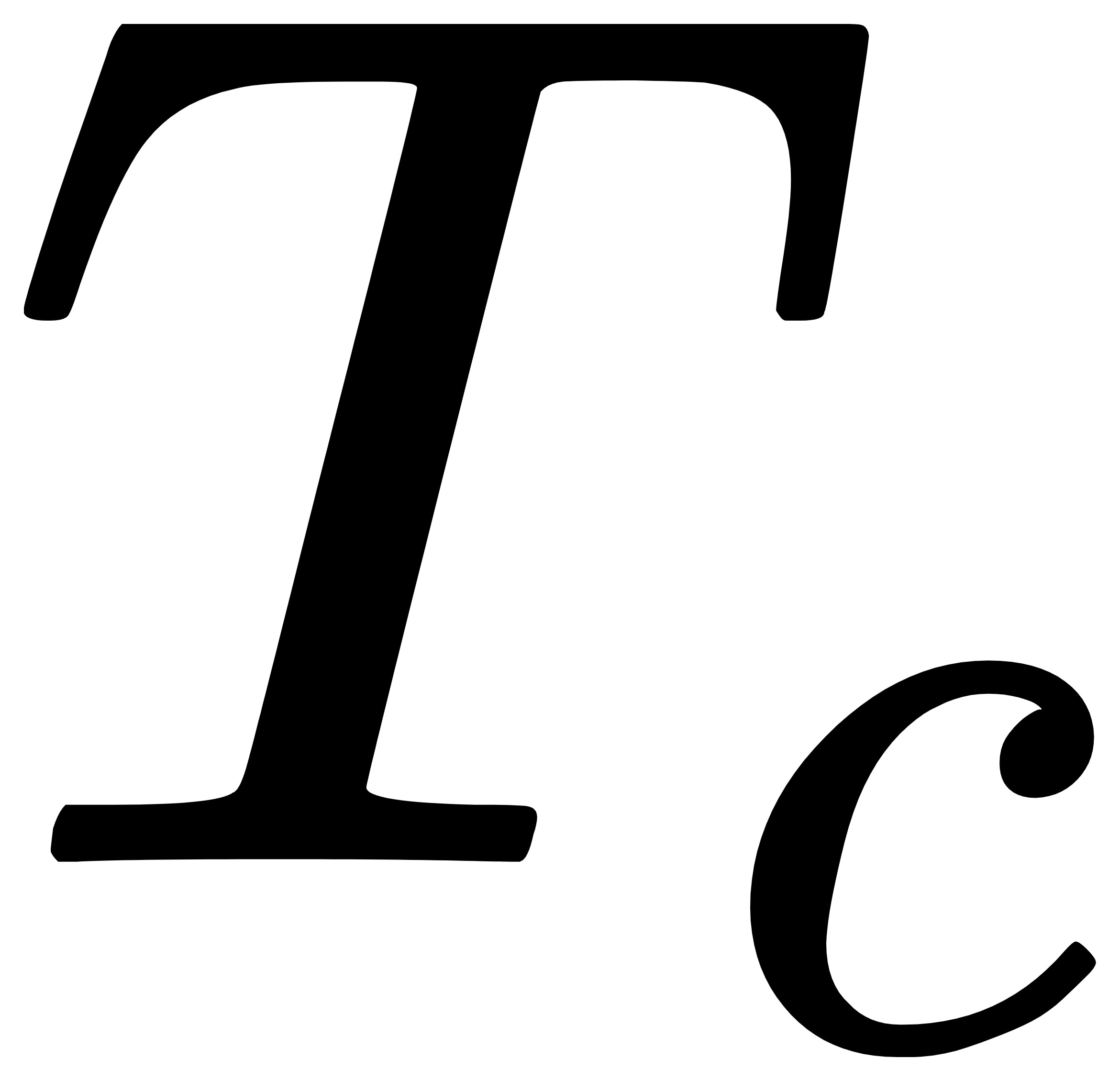 表示当前时刻的时间戳;
表示当前时刻的时间戳;
(2)基准坐标点:监测跑男当前坐标点是否异常的参考坐标点称之为基准坐标点,表示为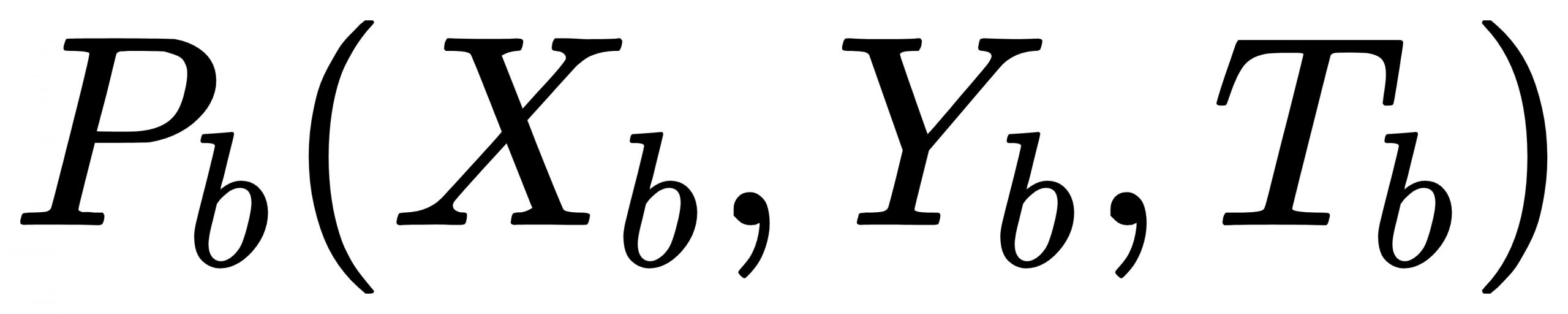 ,其中
,其中 表示基准坐标点所对应的时间戳;
表示基准坐标点所对应的时间戳;
(3)缓存坐标数据集合:跑男当前时刻之前的最新的n条坐标数据组成的集合称之为缓存坐标数据集合,表示为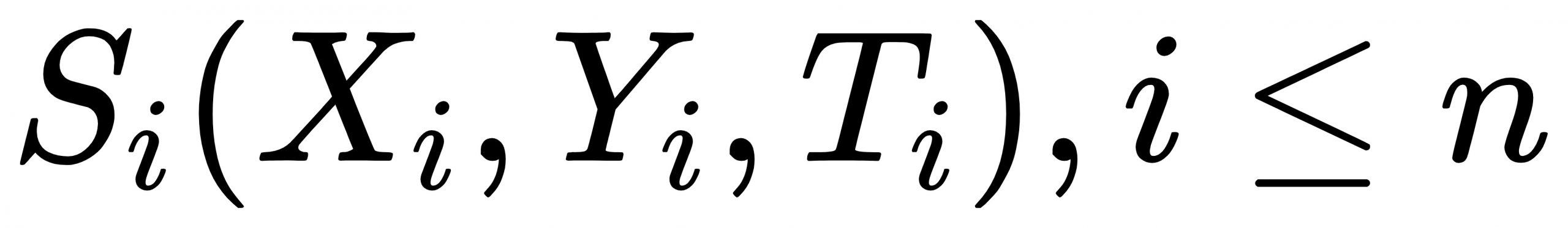 ;
;
(4)跑男行驶速度:跑男在接送单过程中的平均速度,表示为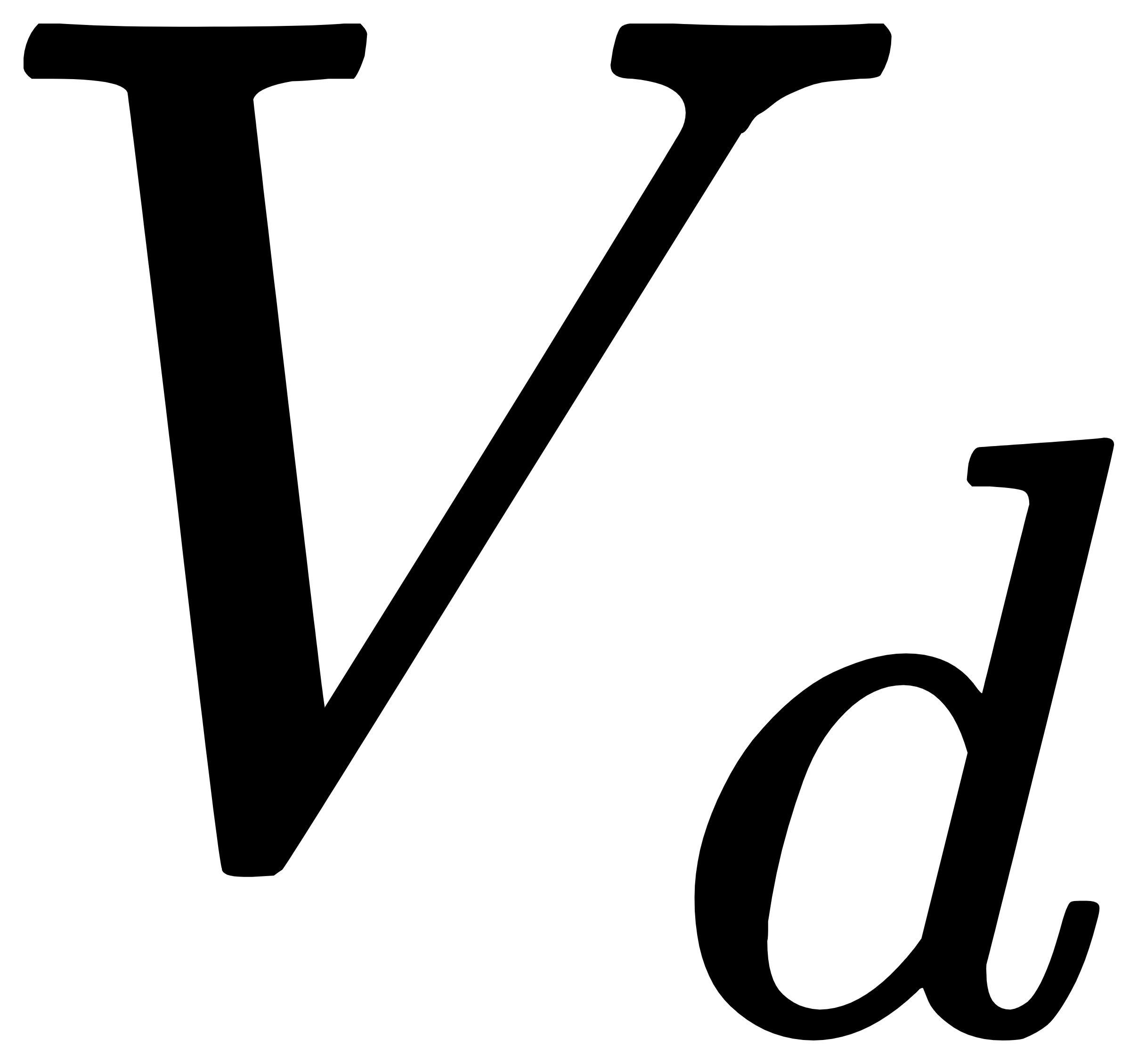 。
。
算法实现步骤:
步骤1:初始化程序,获取跑男当前时刻坐标点  ;
;
步骤2:如果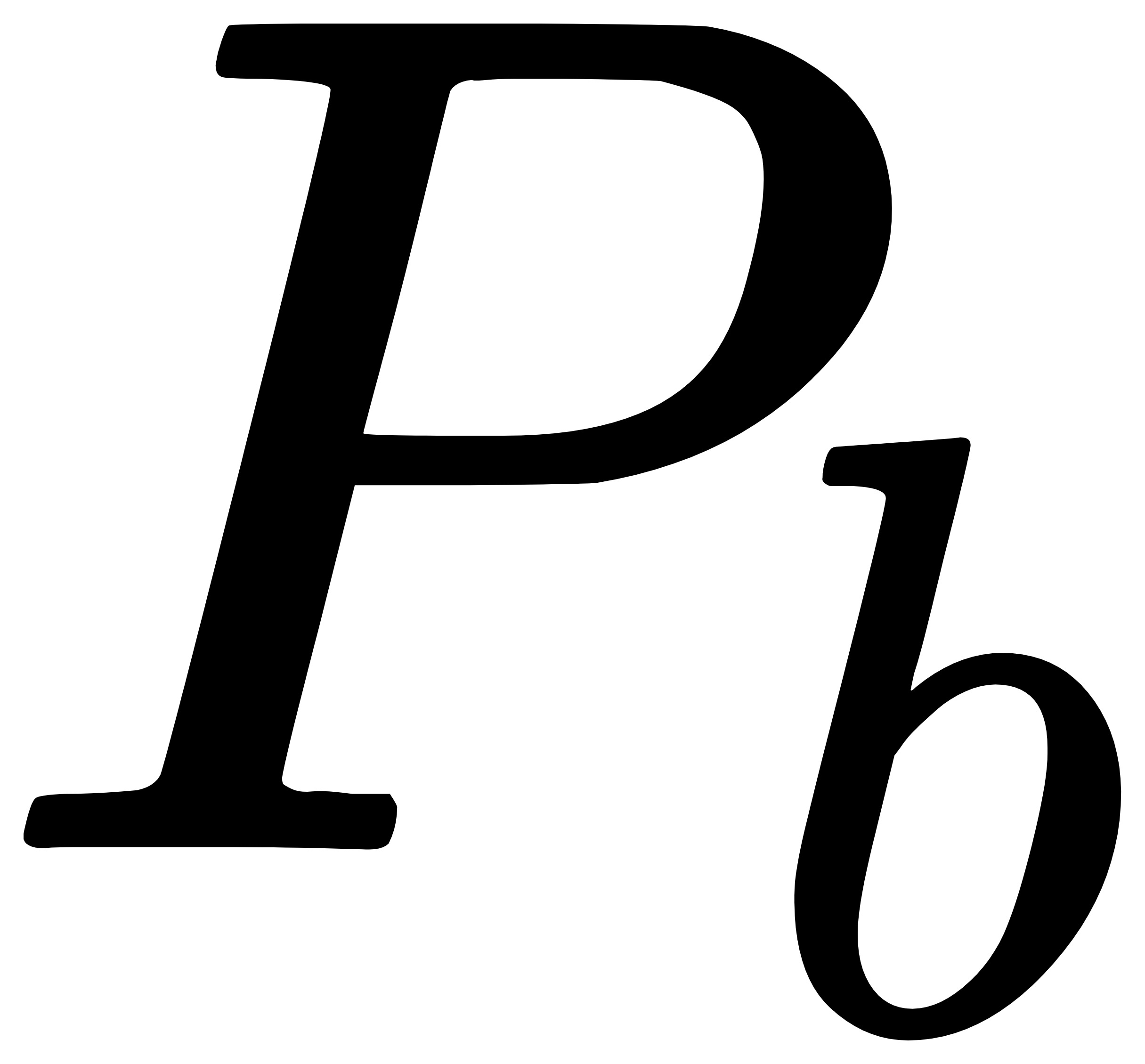 为空,则判定为非异常坐标点,同时,将赋值给 ,并把坐标点添加至缓存坐标数据集合
为空,则判定为非异常坐标点,同时,将赋值给 ,并把坐标点添加至缓存坐标数据集合 中,然后转至步骤8;
中,然后转至步骤8;
步骤3:如果不为空,通过公式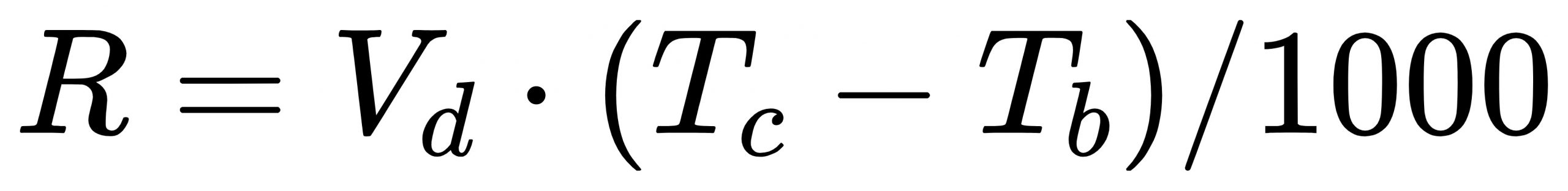 计算出 与 时间点之间跑男行驶的最大距离,然后以 点为中心点,以
计算出 与 时间点之间跑男行驶的最大距离,然后以 点为中心点,以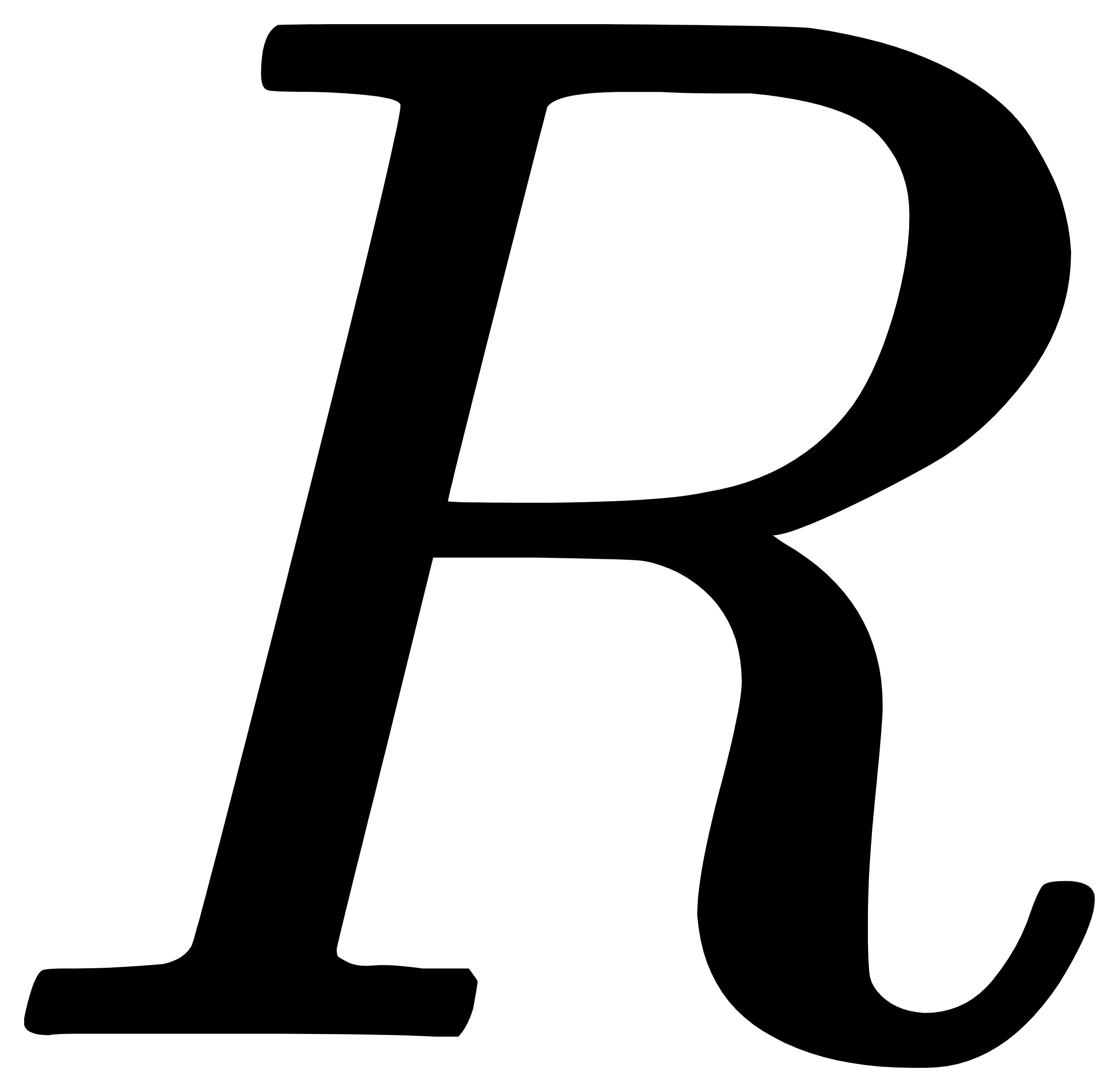 为缓冲区半径创建圆面,并通过GIS中拓扑关系判断 是否在圆面范围内;
为缓冲区半径创建圆面,并通过GIS中拓扑关系判断 是否在圆面范围内;
步骤4:如果 在步骤3中所构建的圆面范围内,则将该点判定为非异常坐标点,同时,更新基准点坐标 为 所包含的值,并将 添加至缓存坐标数据集合 中,然后转至步骤8;
步骤5:如果 不在步骤3所构建的圆面范围内,则判定缓存坐标数据集合 是否包含n条缓存坐标数据,如果不足n条数据,则判定 为异常点,同时,将 添加至缓存坐标数据集合 中,然后转至步骤8,否则,转至步骤6;
步骤6:将点与缓存坐标数据集合 组合成新的坐标集合,调用最大最小距离聚类算法,计算各聚类簇中坐标点个数,选取坐标点个数最多的簇中时间戳最大的点作为暂时的基准坐标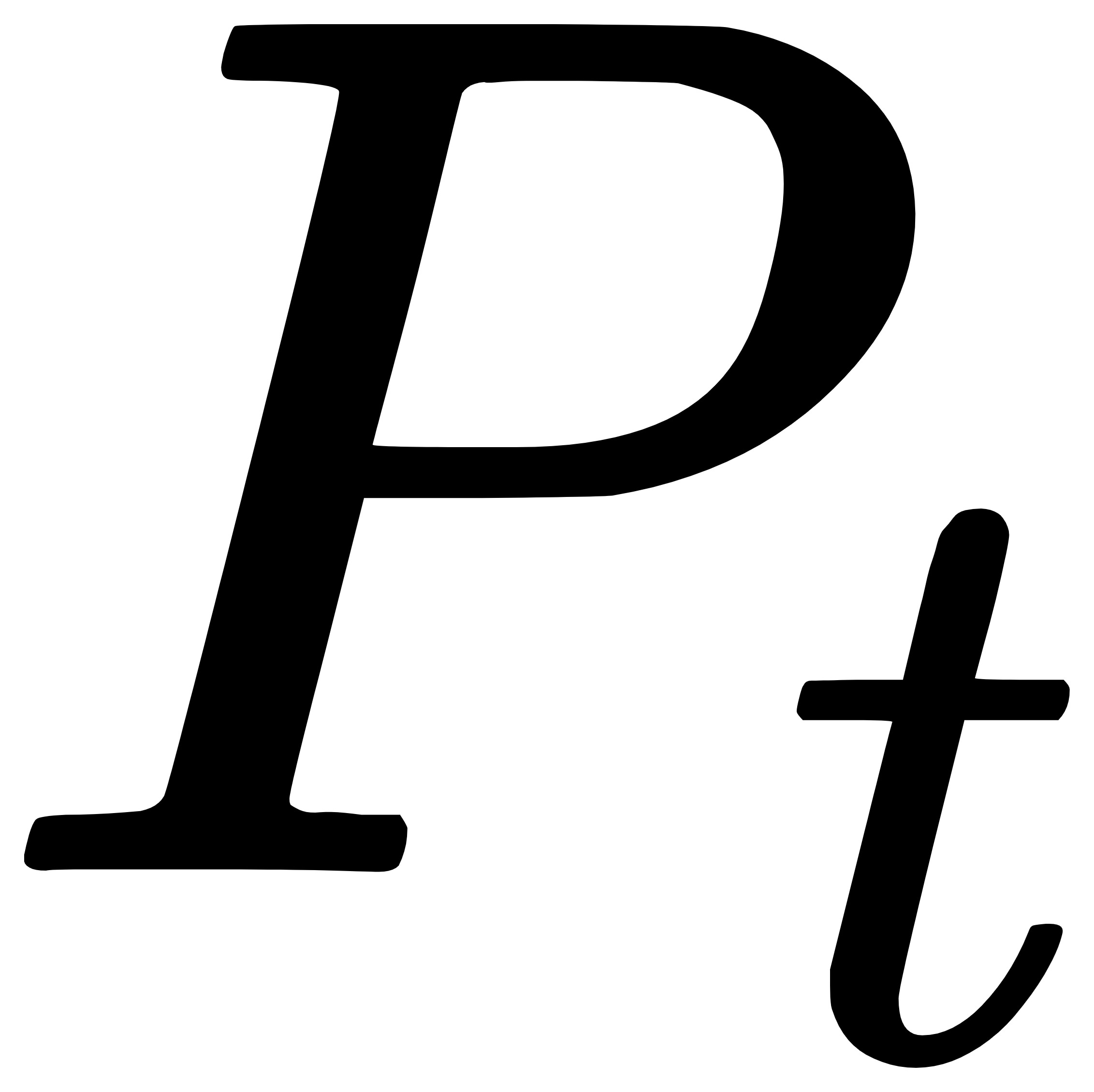 ,采用步骤3的方法,再次判定 是否在基准坐标 构建的圆面范围内;
,采用步骤3的方法,再次判定 是否在基准坐标 构建的圆面范围内;
步骤7:如果 在圆面范围内,则判定该点为非异常点,同时,更新基准坐标点 为 中所包含的值,并将 添加至缓存坐标数据集合 中,然后转至步骤8,否则,判定该点为异常点,转至步骤8;
步骤8:本轮坐标点监测流程结束,并将本轮最终得到的基准坐标点 、缓存坐标数据集合 保存,以备监测下一时间点该跑男定位点的异常情况。
4 应用案例
本文应用实例采用项目中经坐标偏移的跑男定位点数据集进行验证。定位点数据平均每分钟定位两次,定位点个数为600个。数据集格式为.csv格式,每行为一条定位数据,主要包含lat,lon,timestamp等字段,每行之间按照timestamp字段排序。跑男部分时段定位点监测到的异常点结果如图1、图2所示。其中蓝色点为缓存坐标数据集合 中的坐标点,红色点为本文算法监测到的异常点,黑色点为异常点与缓存坐标数据集合作为聚类数据集得到的新的基准坐标点 。

图2 算法监测到的某时段异常点数据分布图a

图3 算法监测到的某时段异常点数据分布图b
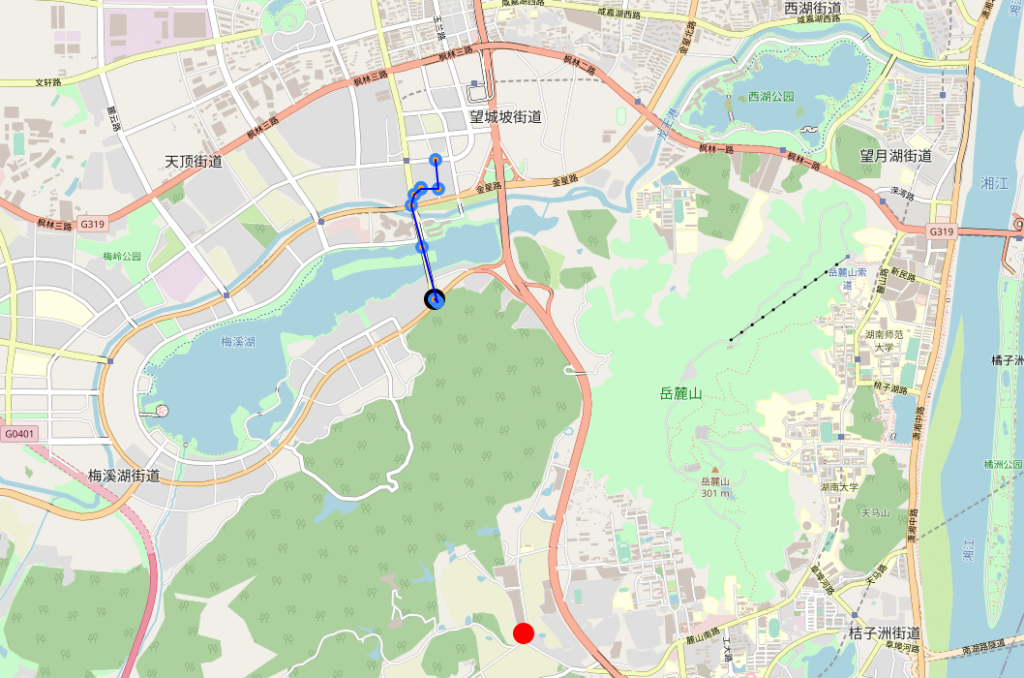
图4 算法监测到的某时段异常点数据分布图c
5 总结与展望
本文介绍了在跑男GPS异常点实时监测方面的探索与实践,在将算法部署到仿真环境中发现跑男定位点的部分坐标点之间的时间间隔较短,如果直接采用时间计算前后两次的时间间隔来确定跑男该时间间隔所能行驶的最大距离,会得到一个较小的距离值,由于跑男定位点本身存在定位精度的问题,因此这种情况得到的距离值不具备参考性,故针对该种情况,需在算法中添加单独的处理逻辑,以保证算法对此种情况不会作出误判。该算法目前所设定的参数并不能适应所有运营城市的情况,后期会观测在生产环境的运行情况,对出现误判的数据进行分析,进一步优化算法。