
背景
为了满足用户在订单配送服务过程中对配送物品位置的高实时性要求,需要提高跑男上报位置信息的频次。现有跑男每日上报了数亿条的订单轨迹数据,面对如此大量的数据,系统原有的订单轨迹存储方案已经无法满足写入和查询的性能需要,已经出现了位置信息的延迟。
设计目标
- 至少满足单日上报 10 亿以上轨迹信息的处理能力
- 满足高峰时段上报 QPS>1W 的处理能力
- 满足进行中订单轨迹查看 QPS>2K 的处理能力
- 历史订单轨迹信息永久保存并且成本可控
- 有水平扩展能力,能够快速扩容
方案设计
同城即时服务的订单生命周期比较短,大部分在 1 小时左右,并且冷热数据区分明显。进行中订单是热数据,用户关注度非常高,会频繁查看订单轨迹和跑男位置。已完结订单是冷数据,用户基本上不查看历史订单轨迹,一般只有客服会在产生客诉时查看历史订单的轨迹信息。订单轨迹信息是不可逆的数据,跑男一旦上报位置信息,将不可修改。
针对订单轨迹数据的这些特点,将实时订单和完结订单采用不同的存储方案。
一. 实时订单轨迹
1、已跑男记录轨迹
原有设计是按照订单来存储轨迹信息的,每次跑男位置上报后,都需要反查跑男的进行中订单;如果跑男同时进行的订单有多条,在写入轨迹信息时还需要写多条轨迹信息(每个订单一条)。在位置上报这个场景下都造成了非常高的额外的性能开销。
2、使用 Redis 的 SortedSet 存储轨迹信息
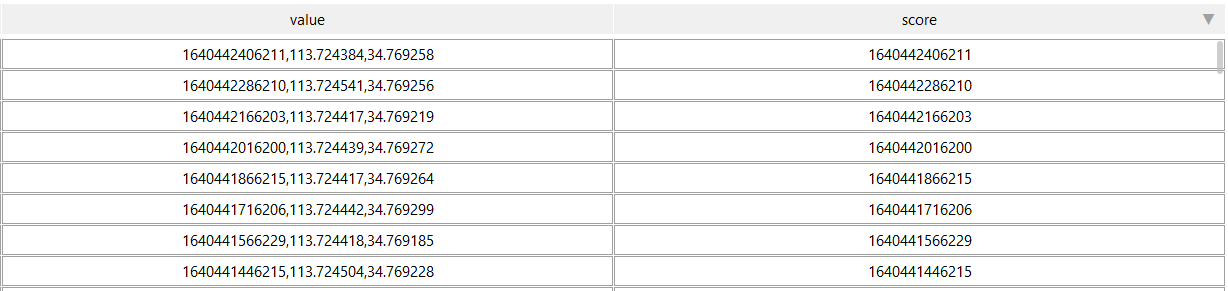
方案设计的位置上报频次是 30 秒一次,QPS 也至少是 1W 以上的。因为轨迹信息是按照跑男记录的,在查询订单轨迹时,就需要按照订单的开始、结束时间查询对应跑男在这段时间内的轨迹信息。综合需要,选择了 Redis 数据的SortedSet 结构类型,既提供了高性能,又可以实现范围内的轨迹查询。
3、每个跑男每天一个键
根据 30 秒一次位置上报和一天接单时间 14 小时估算,跑男一天的轨迹信息约 1680 条,使用Redis 的 SortedSet 缓存约占用 230KB。
4、缓存保留 2 天
虽然一般的配送订单时间都在 1 小时内,但考虑到跨天和客诉场景,跑男轨迹会在缓存中保存 2 天,基本上保证 95% 以上的订单轨迹查询场景都使用 Redis 缓存。
5、过滤异常移动
在记录轨迹信息时,会先获取到跑男的最后轨迹信息进行检查,如果移动距离过短或过长都将放弃轨迹的记录。
二. 完结订单轨迹转储
1、异步转储
订单完结后,通过异步任务的方式转储订单轨迹。需要转储的场景包括:订单取消,订单完成,订单跑男变更等。
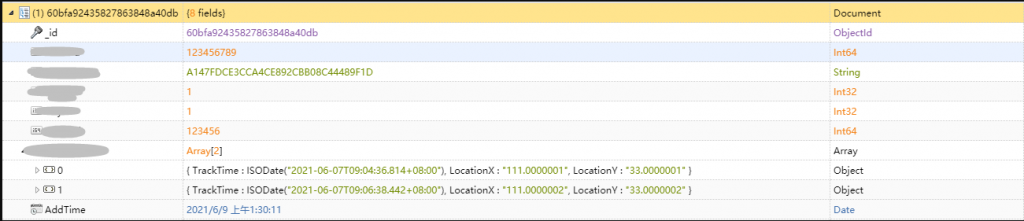
2、转储 MongoDB
转储后的订单轨迹信息仍然有部分查询需要,而且一般单个订单的轨迹信息数量在 100 左右,使用 MongoDB 的数组字段,既有比较好的查询性能,又比较节省存储成本。
3、完结订单轨迹按月分表
数据存储时自动按照订单创建日期按月分表,控制表大小保障数据写入时的性能,越新的数据被查询的概率就越高,同时提升查询性能。
总结
1、轨迹写入性能提升明显
之前的轨迹数据是直接写库,高峰时段异步消息队列的消费速度明显跟不上生产。
新系统上线后,轨迹数据只写 Redis,写入性能大幅提高,未在出现消费不及时的情况。
在订单轨迹转储 MongoDB 后,Redis 中仍然可以查询到最近 2 天的轨迹信息。所以即使订单完结后的转储延迟,也不会对查询订单轨迹造成影响。
2、轨迹准确度提升
由于之前位置上报间隔时间较长,并且轨迹写入可能会延迟,所以订单轨迹不够精确,经常会出现轨迹与实际移动路径偏差过大。
新系统上线后,位置上报间隔变短,订单轨迹中的位置数量增大,并且更新及时、轨迹精确。
3、轨迹存储占用空间降低
之前存储订单轨迹是一个位置信息一条记录,中间包含了大量的相同信息,如订单编号、跑男编号等。
新系统改为一个订单一条记录,将轨迹以数组的方式存储。在轨迹数量增加 2-3 倍的情况下,存储空间的占用反而降低到之前的 30% 左右。