
背景
传统的时间序列异常检测,通常是由人工配置最大最小阈值,超出报警。这种方式非常不灵活,因为不同时段的时间序列分布可能差距较大,就QPS曲线来讲,晚上是低峰时段,白天调用量相对较高,若由人工配置需根据时段设置不同阈值。当然,还存在其他若干不便捷问题。
随着机器学习的发展,将机器学习模型应用于传统运维中的案例也不少,本项目就以腾讯开源项目 Metis 为基础进行二次开发,适用于QPS时间序列的异常检测。
数据
任务类型及数据输入
在建模初期,首先要明确该项目属分类问题,而模型的输入应结合当前时序数据和历史时序数据,对目标点进行预测。
故针对目标值的预测,需依赖三段时序数据,数据选取规则如下图所示。
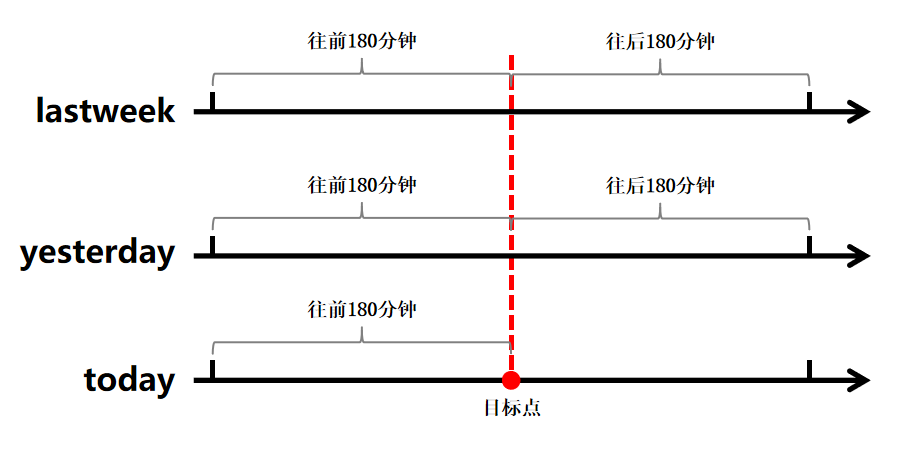
数据来源
从日志中抽取近14天各服务API接口的调用日志,共涉及100+服务,按服务名称、分钟进行聚合,统计QPS数据。
优先使用调用量较高的若干服务,按照数据选取规则,前7天数据作为参考,从第8天凌晨3点开始逐分钟作为目标点构建数据集,单个服务共计9900条数据。
缺失值处理
在真正拿到数据后,发现数据并不是连续的,而是存在很多缺失值,这种数据是不能直接拿来训练模型的。
缺失值的填充主要依靠邻域内的其他数值,具体方法如下。
- 选择邻域范围,随机生成范围区间,通常设置为距离目标点最近的30~60区间;
- 求邻域范围内非零数值的平均值,并作为缺失值的代替值进行填充。
数据可视化
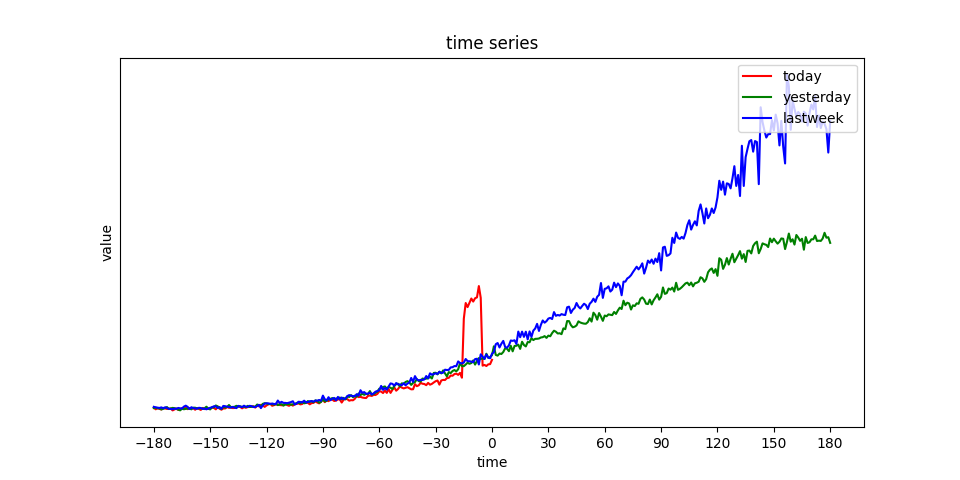
数据可视化的目的有两个:
- 观察当前服务的QPS曲线是否为周期性,即当前时间段的曲线与昨天、上周是否趋势相同;
- 记录异常区间,因日志中并未记录某点是否为异常点,所以需要进行人工标注;
数据不平衡 & 异常注入
一般而言,在样本数据集中,若正负样本分布极度不平衡,那么分类器就会偏向于比例高的那一类样本,导致分类不准确。
在实际生产环境中,对于时序数据QPS来讲,可能99%的数据都是正常的,只有少数是异常的。若直接使用该数据进行训练肯定是不行的,所以需要进行异常注入。
异常注入将在原数据的基础上进行,注入方式有两种:
- 基于3Sigma
- 选择邻域范围,随机生成范围区间,通常设置为距离目标点最近的60~120区间;
- 设置影响范围,随机生成范围区间,通常设置为距离目标点最近的1~5区间,同时随机产生异常衰减方式;
- 设置异常为突增还是突降;
- 结合邻域内数据,计算其均值和方差,根据3Sigma原理,生成超出±3σ的数据作为异常值并替换目标值和影响范围内的数值(注意:针对低峰值场景要给予更高的异常值)。
- 基于倍数
- 选择邻域范围,随机生成范围区间,通常设置为距离目标点最近的60~120区间;
- 设置影响范围,随机生成范围区间,通常设置为距离目标点最近的1~5区间,同时随机产生异常衰减方式;
- 设置异常为突增还是突降;
- 结合邻域内数据,计算其均值,并随机生成异常倍数,使用均值和原数据目标值乘以异常倍数作为异常值并替换目标值和影响范围内的数值(注意:异常倍数范围通常设置为1.3~6倍,针对低峰值场景要给予更高的异常值)。
异常检测模型
模型流程
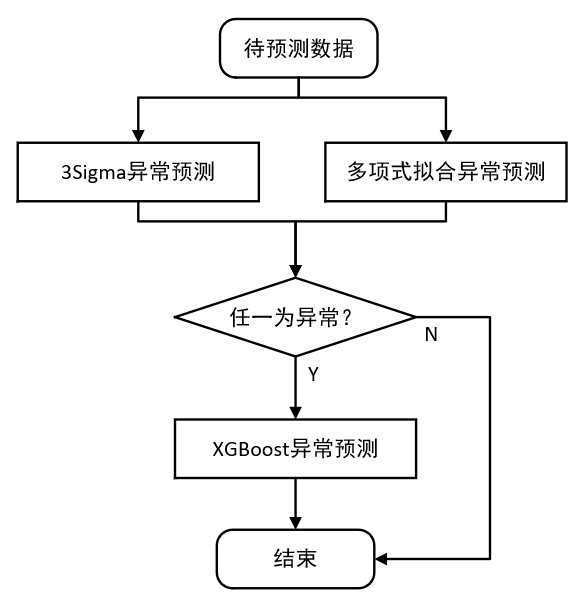
如上图所示,待预测数据先经过3Sigma、多项式拟合两个无监督模型算法进行异常检测,若都为正常则直接结束,若任一模型判定为异常则进行有监督的XGBoost模型算法,并将XGBoost模型的预测结果当作最后返回结果。
3Sigma
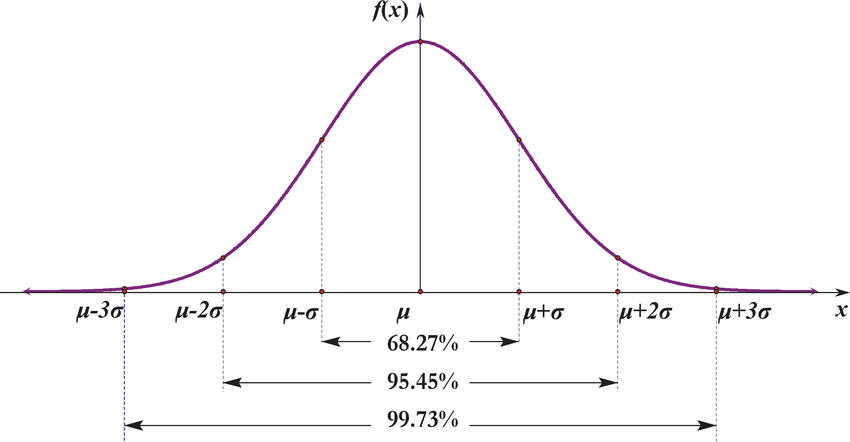
3Sigma假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。
需要注意,在真正使用时,对于常规时序数据来讲阈值取3确实有一定效果,但对于低峰期时序数据却极易产生误报,所以对于低峰期时序数据要给予更大的阈值。
多项式拟合
多项式拟合即根据当前时序数据和历史时序数据,拟合多项式函数,再对目标点进行预测。若预测值在目标值的浮动范围内则认为是正常,否则认为是异常,通常浮动范围设置为目标值的0.8~1.2倍,即上下浮动20%。
与3Sigma相同,对于低峰期时序数据来讲20%的浮动范围极易产生误报,所以对于低峰期时序数据要给予更大的阈值。
XGBoost
XGBoost是对梯度提升算法的改进,求解损失函数极值时使用了牛顿法,将损失函数泰勒展开到二阶,另外损失函数中加入了正则化项。训练时的目标函数由两部分构成,第一部分为梯度提升算法损失,第二部分为正则化项。 模型的细节在此不再重述,重点对于特征的选择给出说明。
该算法从原始时间序列中提取出三类特征:统计特征、拟合特征、分类特征,特征维度90+,下面简述其重要特征。
- 统计特征:最大值、最小值、均值、方差、标准差、中位数、样本偏度、峰度、绝对能量等;
- 拟合特征:移动平均、加权移动平均、指数移动平均、双指数移动平均等;
- 分类特征:自相关、变异系数、元素阈值百分比等;
若干难点解决方法
低峰期场景
初版模型并未考虑到低峰期场景,在部署测试期间极易产生误报,分析后发现误报大多集中在晚上,主要原因是因为晚上服务调用量低。举个例子,假设晚上服务调用量平均在50以下,白天服务调用量平均在2000以上,在这种场景下即使晚上偶尔有个200+的调用量也不奇怪,但是200+却是50的四倍之多,所以算法便将其判定为异常。
既然已知原因,那么就想办法解决。解决方法也并不复杂,首先统计QPS的分布,根据分布情况分区间设置阈值,对于低峰期时序数据要给予更大的阈值。比如对于多项式拟合算法来讲,通常预测值在目标值上下浮动20%以外时会发出报警,这对于低峰期场景是不适用的,故根据时序数据的均值来设置动态阈值。
| mean | threshold |
| 0~100 | 3.1 |
| 100~200 | 1.8 |
| 200~350 | 1.0 |
| 350~500 | 0.5 |
| 500+ | 0.2 |
注:上表中的数据只作为示例参考,并不具有代表性。
节假日场景
模型的思路是根据历史时序数据去预测当前时序数据,所以就存在一个问题,节假日的服务调用量通常比平时大得多,那么依靠平时的数据去预测节假日的数据是不合理的。
事实证明确实如此,该模型在部署测试期间刚好遇到圣诞节,服务的调用量是平时的两倍之多,误报不断。 目前的解决方法是将节假日的实时数据永久保存,在下次节假日期间不再参考前一天和一周前的数据,而是直接使用上一节假日期间的数据作为参考。
模型评估
准确率评估
| P | R | F1 |
| 0.9989 | 0.9994 | 0.9992 |
在部署测试期间,漏报的情况不存在,误报每服务每天大概0~1条,误报率≈0.1%,且泛化能力尚可。
耗时评估
结合模型流程图,若只使用3Sigma、多项式拟合两个无监督模型算法进行异常检测,则耗时4ms左右;若再加上有监督的XGBoost模型算法,则耗时15ms左右。
线上部署
参数说明
使用Django框架进行部署,url地址ip:port/predict/,request和response字段说明如下所示。
request
| 名称 | 类型 | 说明 |
| data_today | str | 待检测的1个点+前180个数据,共181个数据点,181个数据点按时间顺序拼接,英文逗号分隔 |
| data_yesterday | str | 待检测的1个点对应昨日同时刻的点 + 前后各180个数据,361个数据点按时间顺序拼接,英文逗号分隔 |
| data_lastweek | str | 待检测的1个点对应一周前同时刻的点 + 前后各180个数据,361个数据点按时间顺序拼接,英文逗号分隔 |
response
| 名称 | 类型 | 说明 |
| code | int | 返回码。200:成功;400:失败 |
| msg | str | 返回消息 |
| ret | int | 检测结果是否异常。0:异常;1:正常 |
| p | dict | 异常和正常的概率值。如:{"negative": 0.0, "positive": 1.0} |
| detail | dict | 各算法的预测结果详情。如{"statistic_pred": 1, "polynomial_pred": 0, "xgboost_pred": 0} |
实际生产环境的应用
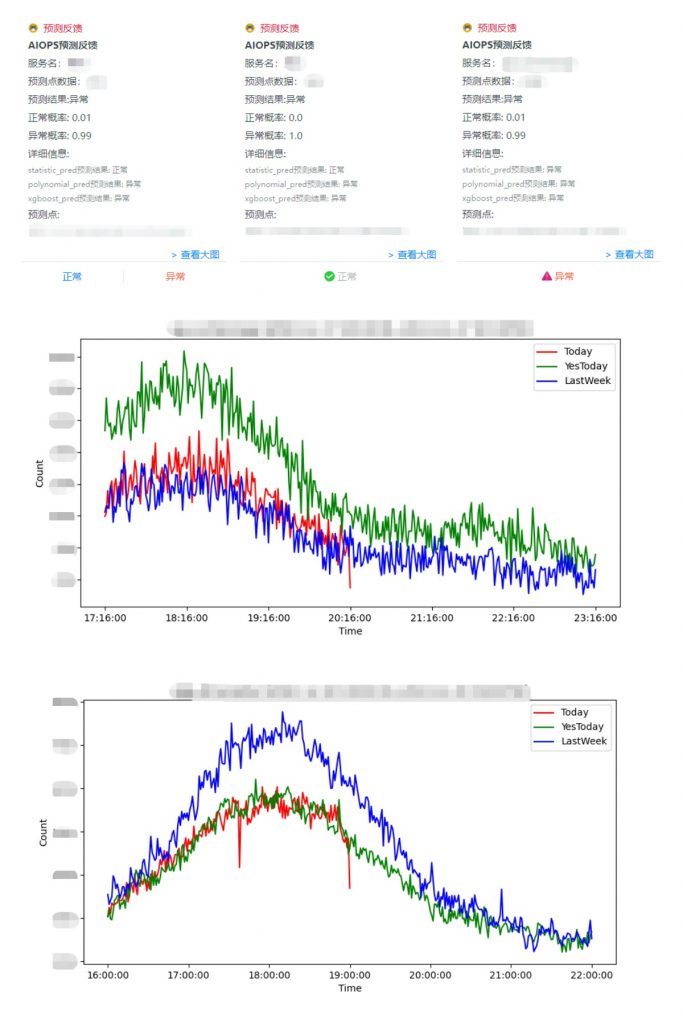
对若干服务的QPS时序数据进行实时监控,若检测为异常则通过钉钉机器人发送详情信息,包含服务名、预测点时间、预测点数据、预测结果、正常概率、异常概率等,除此外还需要发送该时间点的QPS曲线图,方便用户查看、反馈预测结果正确与否。
后续工作
目前第一期的工作暂时完成,只针对QPS进行异常检测,模型先测试一段时间看看效果,第二期可能结合服务API接口的调用耗时情况进一步优化。